publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2024
- Journal
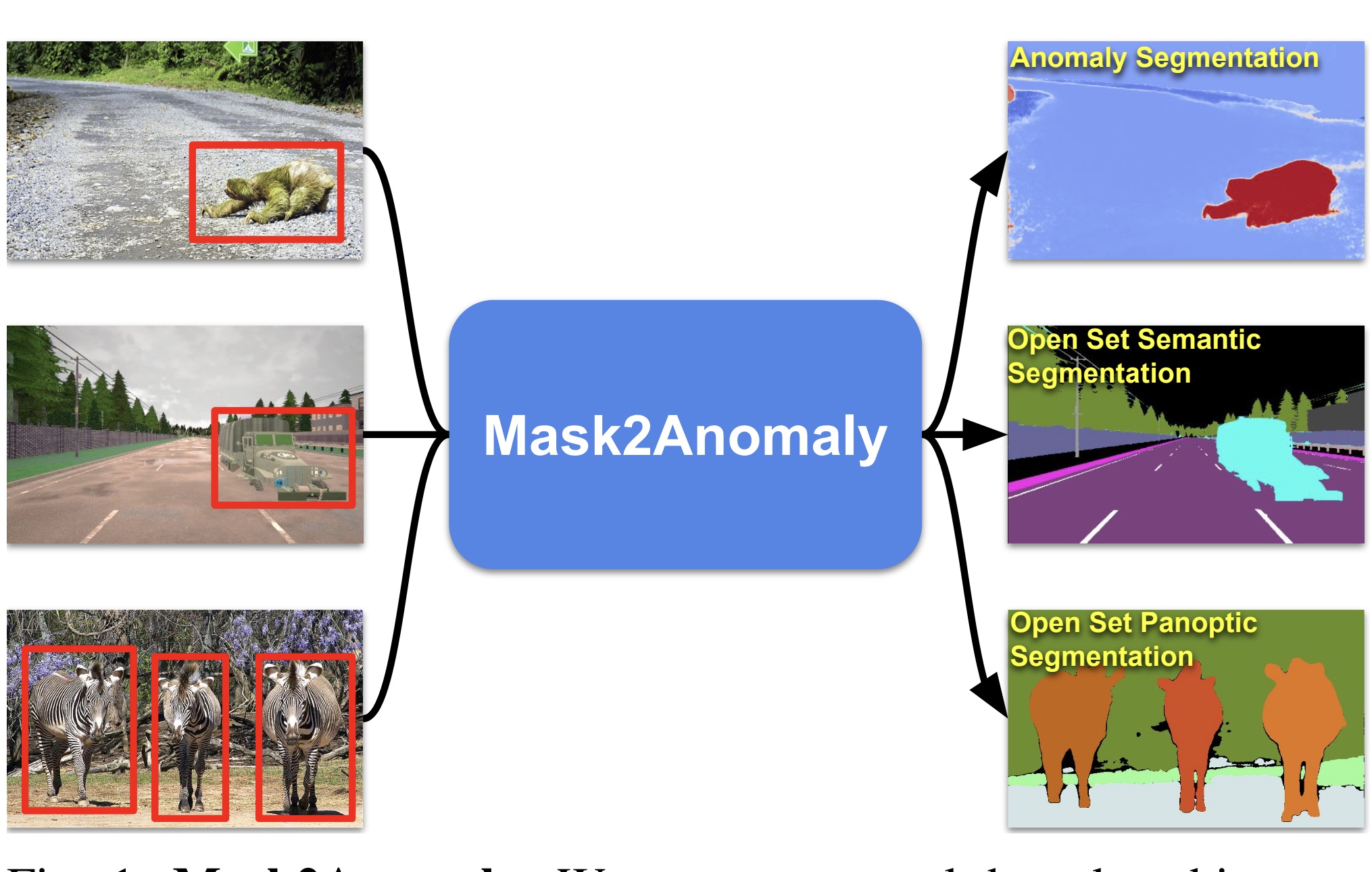 Mask2Anomaly: Mask Transformer for Universal Open-set SegmentationShyam Nandan Rai, Fabio Cermelli, Barbara Caputo, and Carlo MasoneIEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Mask2Anomaly: Mask Transformer for Universal Open-set SegmentationShyam Nandan Rai, Fabio Cermelli, Barbara Caputo, and Carlo MasoneIEEE Transactions on Pattern Analysis and Machine Intelligence, 2024Segmenting unknown or anomalous object instances is a critical task in autonomous driving applications, and it is approached traditionally as a per-pixel classification problem. However, reasoning individually about each pixel without considering their contextual semantics results in high uncertainty around the objects’ boundaries and numerous false positives. We propose a paradigm change by shifting from a per-pixel classification to a mask classification. Our mask-based method, Mask2Anomaly, demonstrates the feasibility of integrating a mask-classification architecture to jointly address anomaly segmentation, open-set semantic segmentation, and open-set panoptic segmentation. Mask2Anomaly includes several technical novelties that are designed to improve the detection of anomalies/unknown objects: i) a global masked attention module to focus individually on the foreground and background regions; ii) a mask contrastive learning that maximizes the margin between an anomaly and known classes; iii) a mask refinement solution to reduce false positives; and iv) a novel approach to mine unknown instances based on the mask- architecture properties. By comprehensive qualitative and qualitative evaluation, we show Mask2Anomaly achieves new state-of-the-art results across the benchmarks of anomaly segmentation, open-set semantic segmentation, and open-set panoptic segmentation.
@article{Rai-2024-mask2anomaly, author = {Rai, Shyam Nandan and Cermelli, Fabio and Caputo, Barbara and Masone, Carlo}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, title = {{Mask2Anomaly}: Mask Transformer for Universal Open-set Segmentation}, year = {2024}, volume = {}, number = {}, pages = {1-17}, doi = {10.1109/TPAMI.2024.3419055}, keywords = {fine grained understanding, driving, uncertainty quantification, spatial intelligence}, } - Conference
 MeshVPR: Citywide Visual Place Recognition Using 3D MeshesGabriele Berton, Lorenz Junglas, Riccardo Zaccone, Thomas Pollok, Barbara Caputo, and Carlo MasoneIn European Conference on Computer Vision (ECCV), 2024
MeshVPR: Citywide Visual Place Recognition Using 3D MeshesGabriele Berton, Lorenz Junglas, Riccardo Zaccone, Thomas Pollok, Barbara Caputo, and Carlo MasoneIn European Conference on Computer Vision (ECCV), 2024Mesh-based scene representation offers a promising direction for simplifying large-scale hierarchical visual localization pipelines, combining a visual place recognition step based on global features (retrieval) and a visual localization step based on local features. While existing work demonstrates the viability of meshes for visual localization, the impact of using synthetic databases rendered from them in visual place recognition remains largely unexplored. In this work we investigate using dense 3D textured meshes for large-scale Visual Place Recognition (VPR). We identify a significant performance drop when using synthetic mesh-based image databases compared to real-world images for retrieval. To address this, we propose MeshVPR, a novel VPR pipeline that utilizes a lightweight features alignment framework to bridge the gap between real-world and synthetic domains. MeshVPR leverages pre-trained VPR models and is efficient and scalable for city-wide deployments. We introduce novel datasets with freely available 3D meshes and manually collected queries from Berlin, Paris, and Melbourne. Extensive evaluations demonstrate that MeshVPR achieves competitive performance with standard VPR pipelines, paving the way for mesh-based localization systems.
@inproceedings{Berton-2024-meshvpr, author = {Berton, Gabriele and Junglas, Lorenz and Zaccone, Riccardo and Pollok, Thomas and Caputo, Barbara and Masone, Carlo}, booktitle = {European Conference on Computer Vision ({ECCV})}, title = {{MeshVPR}: Citywide Visual Place Recognition Using {3D} Meshes}, year = {2024}, volume = {}, number = {}, pages = {1-24}, keywords = {localization, spatial intelligence}, } - Conference
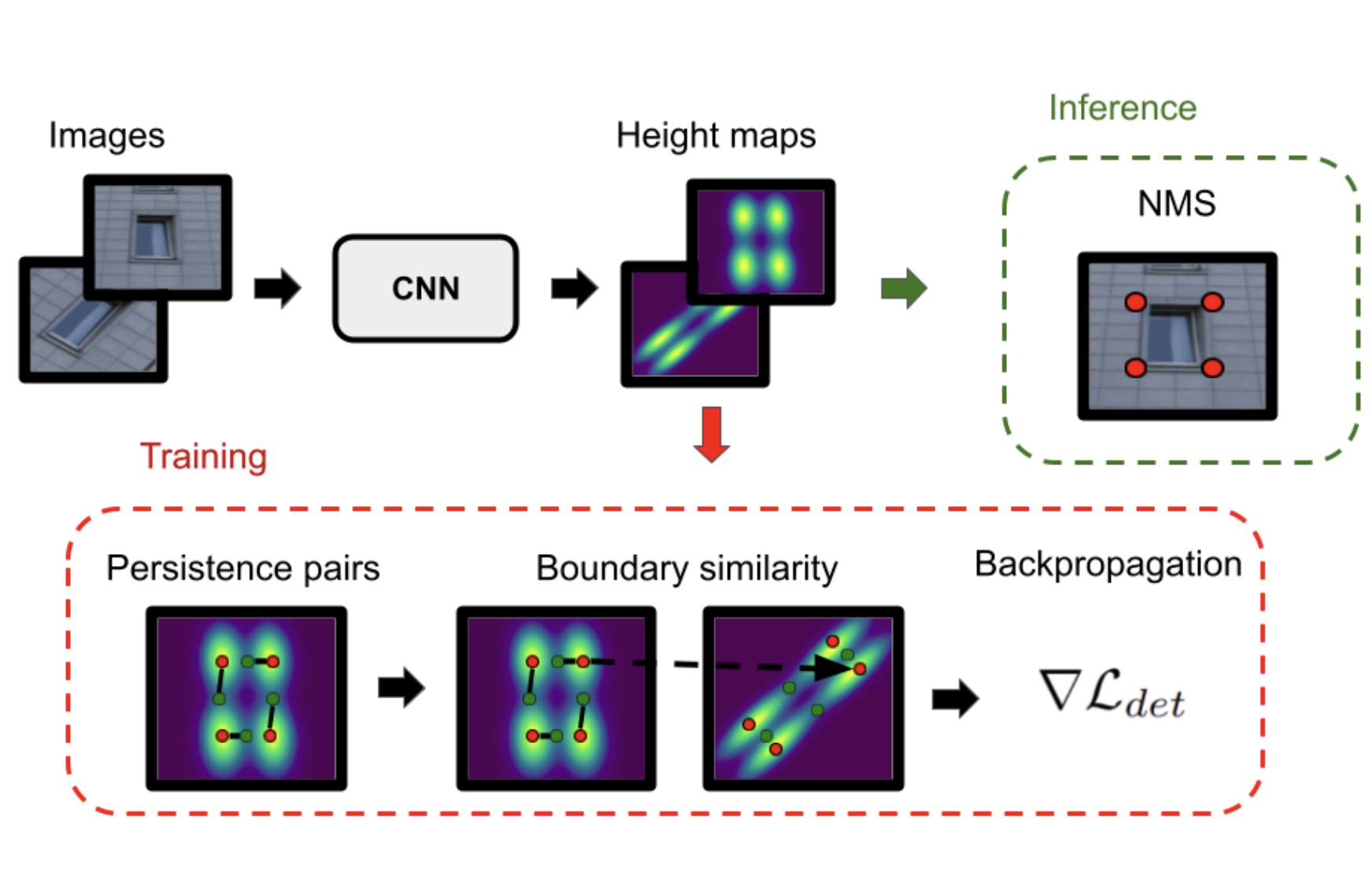 Scale-Free Image Keypoints Using Differentiable Persistent HomologyGiovanni Barbarani, Francesco Vaccarino, Gabriele Trivigno, Marco Guerra, Gabriele Berton, and Carlo MasoneIn International Conference on Machine Learning (ICML), 2024
Scale-Free Image Keypoints Using Differentiable Persistent HomologyGiovanni Barbarani, Francesco Vaccarino, Gabriele Trivigno, Marco Guerra, Gabriele Berton, and Carlo MasoneIn International Conference on Machine Learning (ICML), 2024In computer vision, keypoint detection is a fundamental task, with applications spanning from robotics to image retrieval; however, existing learning-based methods suffer from scale dependency and lack flexibility. This paper introduces a novel approach that leverages Morse theory and persistent homology, powerful tools rooted in algebraic topology. We propose a novel loss function based on the recent introduction of a notion of subgradient in persistent homology, paving the way toward topological learning. Our detector, MorseDet, is the first topology-based learning model for feature detection, which achieves competitive performance in keypoint repeatability and introduces a principled and theoretically robust approach to the problem.
@inproceedings{Barbarani-2024-morsedet, title = {Scale-Free Image Keypoints Using Differentiable Persistent Homology}, author = {Barbarani, Giovanni and Vaccarino, Francesco and Trivigno, Gabriele and Guerra, Marco and Berton, Gabriele and Masone, Carlo}, booktitle = {International Conference on Machine Learning (ICML)}, year = {2024}, keywords = {localization, image matching, topological learning}, } - Workshop
 EarthMatch: Iterative Coregistration for Fine-grained Localization of Astronaut PhotographyGabriele Berton, Gabriele Goletto, Gabriele Trivigno, Alex Stoken, Barbara Caputo, and Carlo MasoneIn IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Jun 2024
EarthMatch: Iterative Coregistration for Fine-grained Localization of Astronaut PhotographyGabriele Berton, Gabriele Goletto, Gabriele Trivigno, Alex Stoken, Barbara Caputo, and Carlo MasoneIn IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Jun 2024Precise, pixel-wise geolocalization of astronaut photography is critical to unlocking the potential of this unique type of remotely sensed Earth data, particularly for its use in disaster management and climate change research. Recent works have established the Astronaut Photography Localization task, but have either proved too costly for mass deployment or generated too coarse a localization. Thus, we present EarthMatch, an iterative homography estimation method that produces fine-grained localization of astronaut photographs while maintaining an emphasis on speed. We refocus the astronaut photography benchmark, AIMS, on the geolocalization task itself, and prove our method’s efficacy on this dataset. In addition, we offer a new, fair method for image matcher comparison, and an extensive evaluation of different matching models within our localization pipeline. Our method will enable fast and accurate localization of the 4.5 million and growing collection of astronaut photography of Earth.
@inproceedings{Berton-2024-earthmatch, author = {Berton, Gabriele and Goletto, Gabriele and Trivigno, Gabriele and Stoken, Alex and Caputo, Barbara and Masone, Carlo}, title = {{EarthMatch}: Iterative Coregistration for Fine-grained Localization of Astronaut Photography}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}, month = jun, year = {2024}, pages = {4264-4274}, keywords = {localization, spatial intelligence, space}, } - Journal
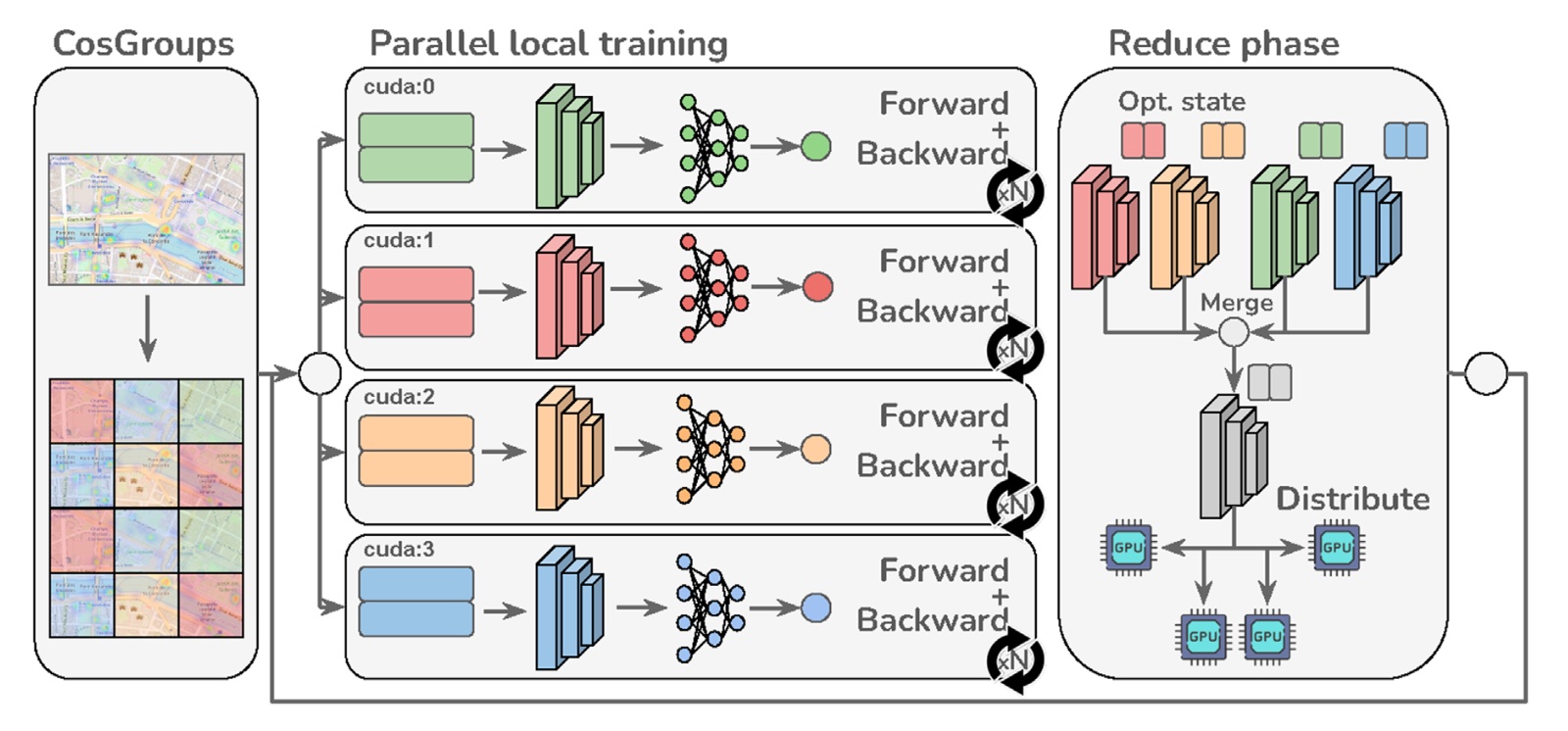 Distributed training of CosPlace for large-scale visual place recognitionRiccardo Zaccone, Gabriele Berton, and Carlo MasoneFrontiers in Robotics and AI, Jun 2024
Distributed training of CosPlace for large-scale visual place recognitionRiccardo Zaccone, Gabriele Berton, and Carlo MasoneFrontiers in Robotics and AI, Jun 2024Visual place recognition (VPR) is a popular computer vision task aimed at recognizing the geographic location of a visual query, usually within a tolerance of a few meters. Modern approaches address VPR from an image retrieval standpoint using a kNN on top of embeddings extracted by a deep neural network from both the query and images in a database. Although most of these approaches rely on contrastive learning, which limits their ability to be trained on large-scale datasets (due to mining), the recently reported CosPlace proposes an alternative training paradigm using a classification task as the proxy. This has been shown to be effective in expanding the potential of VPR models to learn from large-scale and fine-grained datasets. In this work, we experimentally analyze CosPlace from a continual learning perspective and show that its sequential training procedure leads to suboptimal results. As a solution, we propose a different formulation that not only solves the pitfalls of the original training strategy effectively but also enables faster and more efficient distributed training. Finally, we discuss the open challenges in further speeding up large-scale image retrieval for VPR.
@article{Zaccone-2024-dCosplace, title = {Distributed training of CosPlace for large-scale visual place recognition}, author = {Zaccone, Riccardo and Berton, Gabriele and Masone, Carlo}, journal = {Frontiers in Robotics and AI}, volume = {11}, pages = {1-11}, year = {2024}, publisher = {Frontiers Media SA}, doi = {10.3389/frobt.2024.1386464}, keywords = {localization, spatial intelligence, distributed learning}, } - Conference
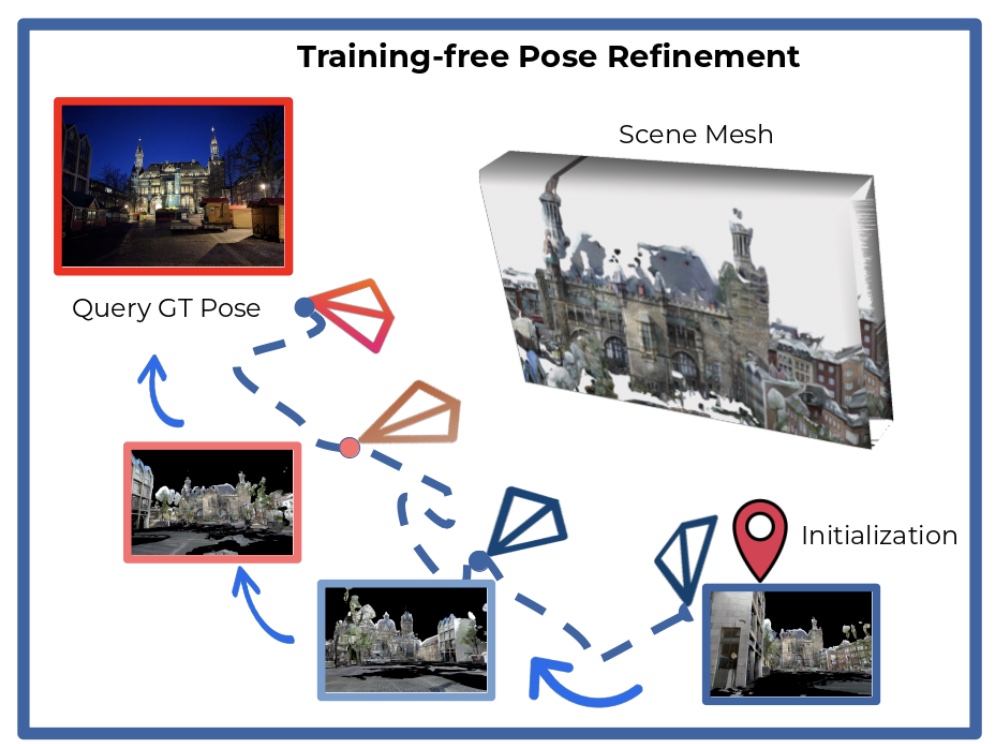 The Unreasonable Effectiveness of Pre-Trained Features for Camera Pose RefinementGabriele Trivigno, Carlo Masone, Barbara Caputo, and Torsten SattlerIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024
The Unreasonable Effectiveness of Pre-Trained Features for Camera Pose RefinementGabriele Trivigno, Carlo Masone, Barbara Caputo, and Torsten SattlerIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024Among the top 10% of accepted papers.
Pose refinement is an interesting and practically relevant research direction. Pose refinement can be used to (1) obtain a more accurate pose estimate from an initial prior (e.g. from retrieval) (2) as pre-processing i.e. to provide a better starting point to a more expensive pose estimator (3) as post-processing of a more accurate localizer. Existing approaches focus on learning features / scene representations for the pose refinement task. This involves training an implicit scene representation or learning features while optimizing a camera pose-based loss. A natural question is whether training specific features / representations is truly necessary or whether similar results can be already achieved with more generic features. In this work we present a simple approach that combines pre-trained features with a particle filter and a renderable representation of the scene. Despite its simplicity it achieves state-of-the-art results demonstrating that one can easily build a pose refiner without the need for specific training.
@inproceedings{Trivigno-2024-unreasonable, author = {Trivigno, Gabriele and Masone, Carlo and Caputo, Barbara and Sattler, Torsten}, title = {The Unreasonable Effectiveness of Pre-Trained Features for Camera Pose Refinement}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, year = {2024}, pages = {12786-12798}, keywords = {localization, spatial intelligence}, } - Workshop
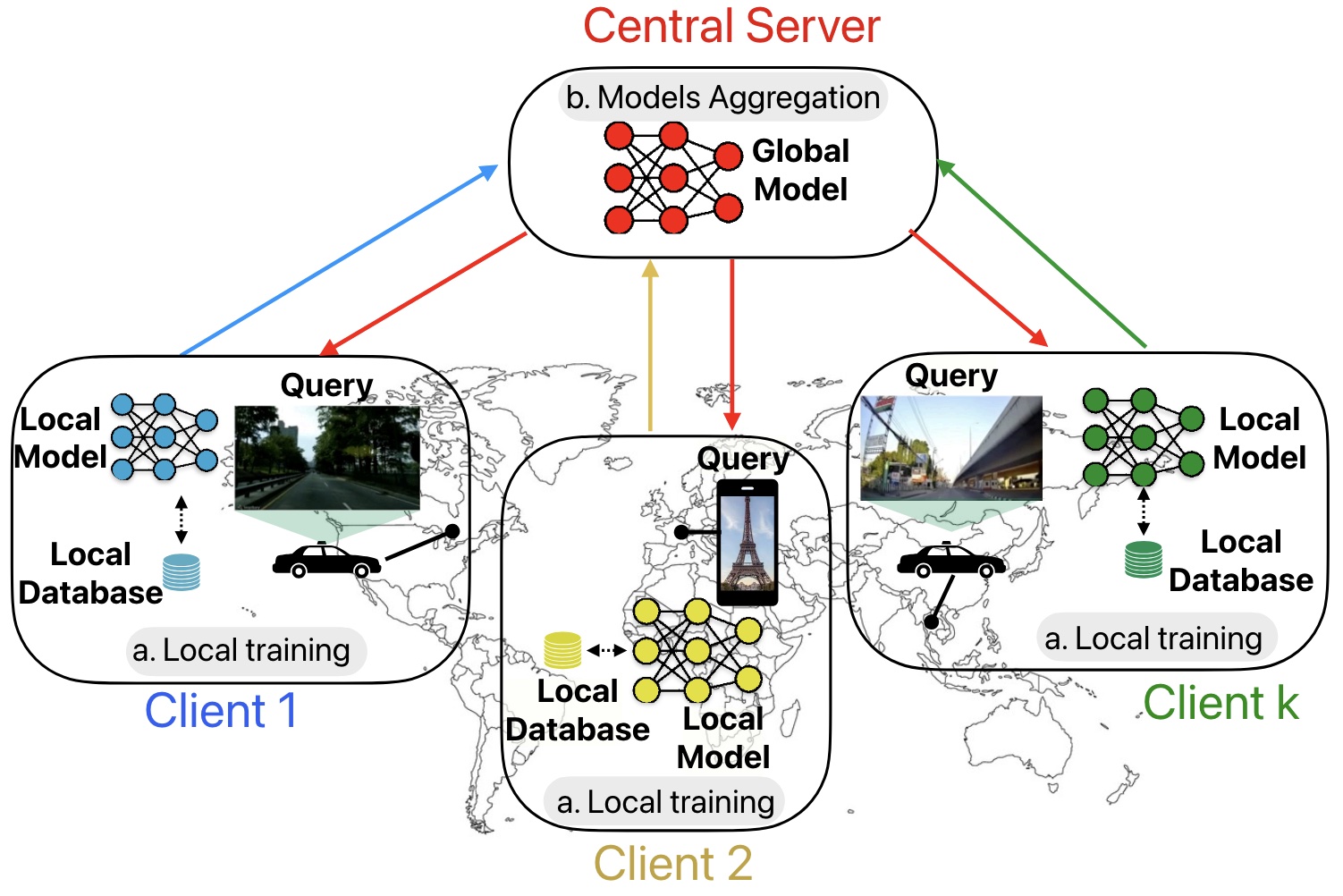 Collaborative Visual Place Recognition through Federated LearningMattia Dutto, Gabriele Berton, Debora Caldarola, Eros Fanı̀, Gabriele Trivigno, and Carlo MasoneIn IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Jun 2024
Collaborative Visual Place Recognition through Federated LearningMattia Dutto, Gabriele Berton, Debora Caldarola, Eros Fanı̀, Gabriele Trivigno, and Carlo MasoneIn IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Jun 2024Visual Place Recognition (VPR) aims to estimate the location of an image by treating it as a retrieval problem. VPR uses a database of geo-tagged images and leverages deep neural networks to extract a global representation called descriptor from each image. While the training data for VPR models often originates from diverse geographically scattered sources (geo-tagged images) the training process itself is typically assumed to be centralized. This research revisits the task of VPR through the lens of Federated Learning (FL) addressing several key challenges associated with this adaptation. VPR data inherently lacks well-defined classes and models are typically trained using contrastive learning which necessitates a data mining step on a centralized database. Additionally client devices in federated systems can be highly heterogeneous in terms of their processing capabilities. The proposed FedVPR framework not only presents a novel approach for VPR but also introduces a new challenging and realistic task for FL research. This has the potential to spur the application of FL to other image retrieval tasks.
@inproceedings{Dutto-2024-fedvpr, author = {Dutto, Mattia and Berton, Gabriele and Caldarola, Debora and Fan{\`\i}, Eros and Trivigno, Gabriele and Masone, Carlo}, title = {Collaborative Visual Place Recognition through Federated Learning}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}, month = jun, year = {2024}, pages = {4215-4225}, keywords = {localization, spatial intelligence, distributed learning}, } - Conference
 Earthloc: Astronaut photography localization by indexing earth from spaceGabriele Berton, Alex Stoken, Barbara Caputo, and Carlo MasoneIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024
Earthloc: Astronaut photography localization by indexing earth from spaceGabriele Berton, Alex Stoken, Barbara Caputo, and Carlo MasoneIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024Astronaut photography, spanning six decades of human spaceflight, presents a unique Earth observations dataset with immense value for both scientific research and disaster response. Despite its significance, accurately localizing the geographical extent of these images, crucial for effective utilization, poses substantial challenges. Current manual localization efforts are time-consuming, motivating the need for automated solutions. We propose a novel approach - leveraging image retrieval - to address this challenge efficiently. We introduce innovative training techniques, including Year-Wise Data Augmentation and a Neutral-Aware Multi-Similarity Loss, which contribute to the development of a high-performance model, EarthLoc. We develop six evaluation datasets and perform a comprehensive benchmark comparing EarthLoc to existing methods, showcasing its superior efficiency and accuracy. Our approach marks a significant advancement in automating the localization of astronaut photography, which will help bridge a critical gap in Earth observations data.
@inproceedings{Berton-2024-earthloc, title = {{Earthloc}: Astronaut photography localization by indexing earth from space}, author = {Berton, Gabriele and Stoken, Alex and Caputo, Barbara and Masone, Carlo}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {12754--12764}, year = {2024}, keywords = {localization, spatial intelligence, space}, } - Journal
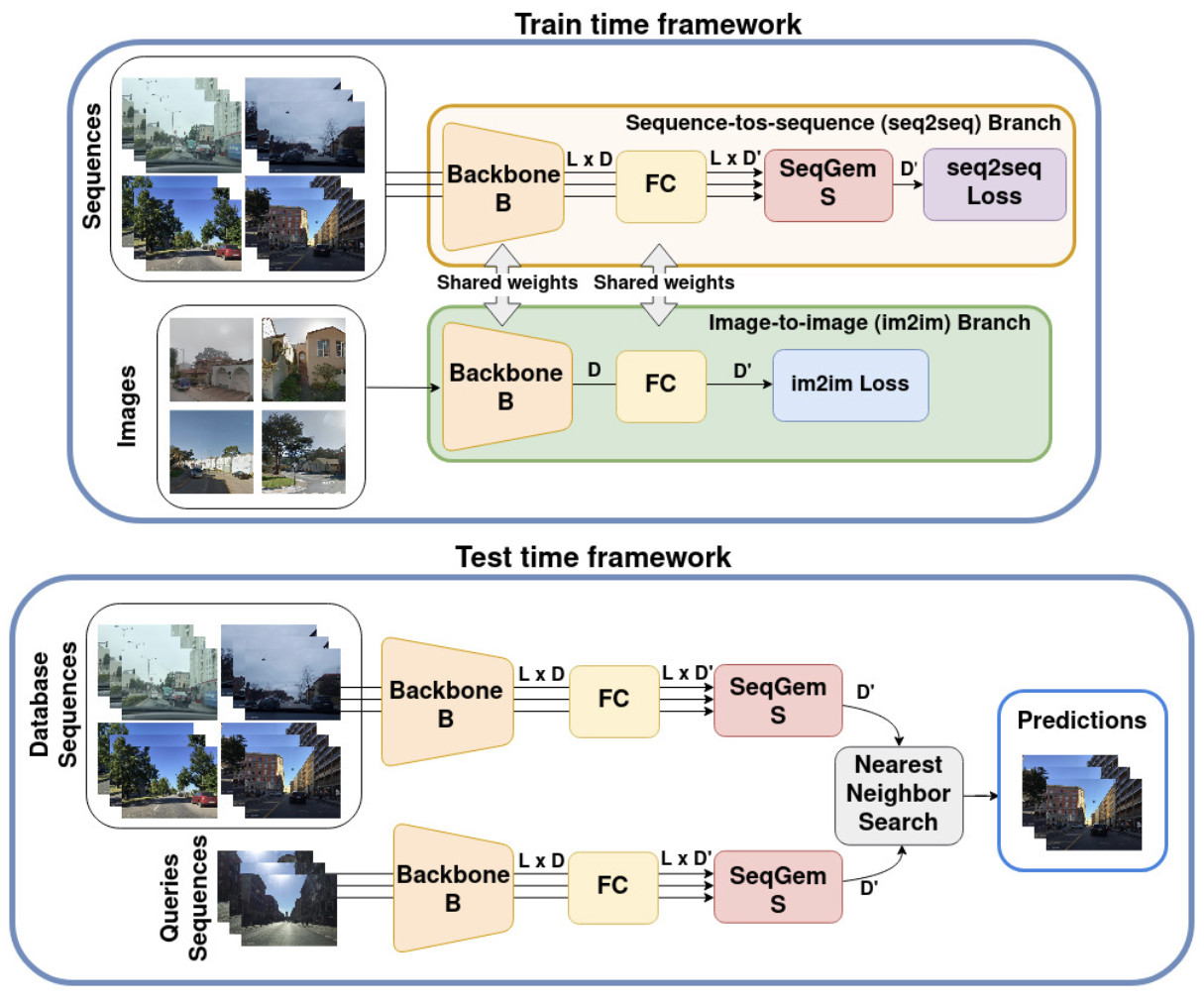 JIST: Joint Image and Sequence Training for Sequential Visual Place RecognitionGabriele Berton, Gabriele Trivigno, Barbara Caputo, and Carlo MasoneIEEE Robotics and Automation Letters, Jun 2024
JIST: Joint Image and Sequence Training for Sequential Visual Place RecognitionGabriele Berton, Gabriele Trivigno, Barbara Caputo, and Carlo MasoneIEEE Robotics and Automation Letters, Jun 2024Visual Place Recognition aims at recognizing previously visited places by relying on visual clues, and it is used in robotics applications for SLAM and localization. Since typically a mobile robot has access to a continuous stream of frames, this task is naturally cast as a sequence-to-sequence localization problem. Nevertheless, obtaining sequences of labelled data is much more expensive than collecting isolated images, which can be done in an automated way with little supervision. As a mitigation to this problem, we propose a novel Joint Image and Sequence Training protocol (JIST) that leverages large uncurated sets of images through a multi-task learning framework. With JIST we also introduce SeqGeM, an aggregation layer that revisits the popular GeM pooling to produce a single robust and compact embedding from a sequence of single-frame embeddings. We show that our model is able to outperform previous state of the art while being faster, using 8 times smaller descriptors, having a lighter architecture and allowing to process sequences of various lengths.
@article{Berton-2024-jist, author = {Berton, Gabriele and Trivigno, Gabriele and Caputo, Barbara and Masone, Carlo}, journal = {IEEE Robotics and Automation Letters}, title = {{JIST}: Joint Image and Sequence Training for Sequential Visual Place Recognition}, year = {2024}, volume = {9}, number = {2}, pages = {1310-1317}, doi = {10.1109/LRA.2023.3339058}, keywords = {localization, spatial intelligence}, }









2023
- Preprint
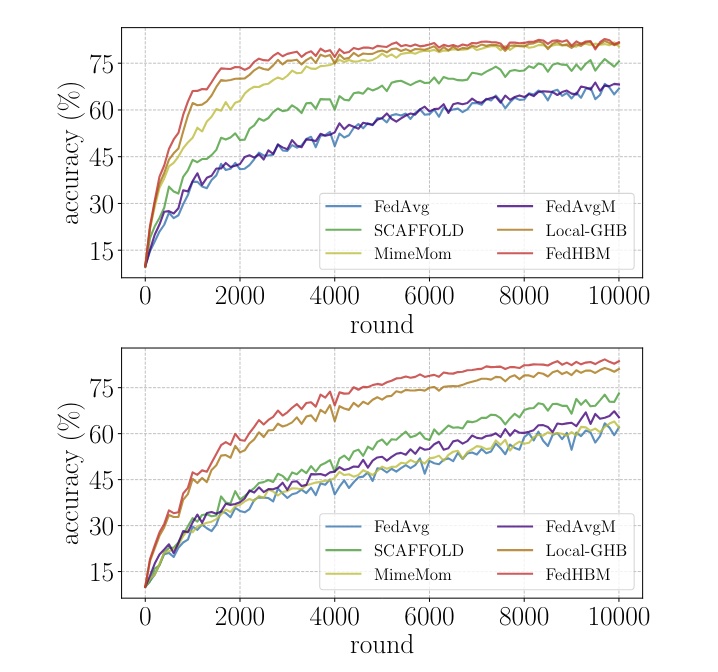 Communication-Efficient Heterogeneous Federated Learning with Generalized Heavy-Ball MomentumRiccardo Zaccone, Carlo Masone, and Marco CicconeJun 2023
Communication-Efficient Heterogeneous Federated Learning with Generalized Heavy-Ball MomentumRiccardo Zaccone, Carlo Masone, and Marco CicconeJun 2023Federated Learning (FL) has emerged as the state-of-the-art approach for learning from decentralized data in privacy-constrained scenarios. However, system and statistical challenges hinder real-world applications, which demand efficient learning from edge devices and robustness to heterogeneity. Despite significant research efforts, existing approaches (i) are not sufficiently robust, (ii) do not perform well in large-scale scenarios, and (iii) are not communication efficient. In this work, we propose a novel Generalized Heavy-Ball Momentum (GHBM), motivating its principled application to counteract the effects of statistical heterogeneity in FL. Then, we present FedHBM as an adaptive, communication-efficient by-design instance of GHBM. Extensive experimentation on vision and language tasks, in both controlled and realistic large-scale scenarios, provides compelling evidence of substantial and consistent performance gains over the state of the art.
@misc{Zaccone-2024-fedhbm, title = {Communication-Efficient Heterogeneous Federated Learning with Generalized Heavy-Ball Momentum}, author = {Zaccone, Riccardo and Masone, Carlo and Ciccone, Marco}, year = {2023}, keywords = {distributed learning}, } - Journal
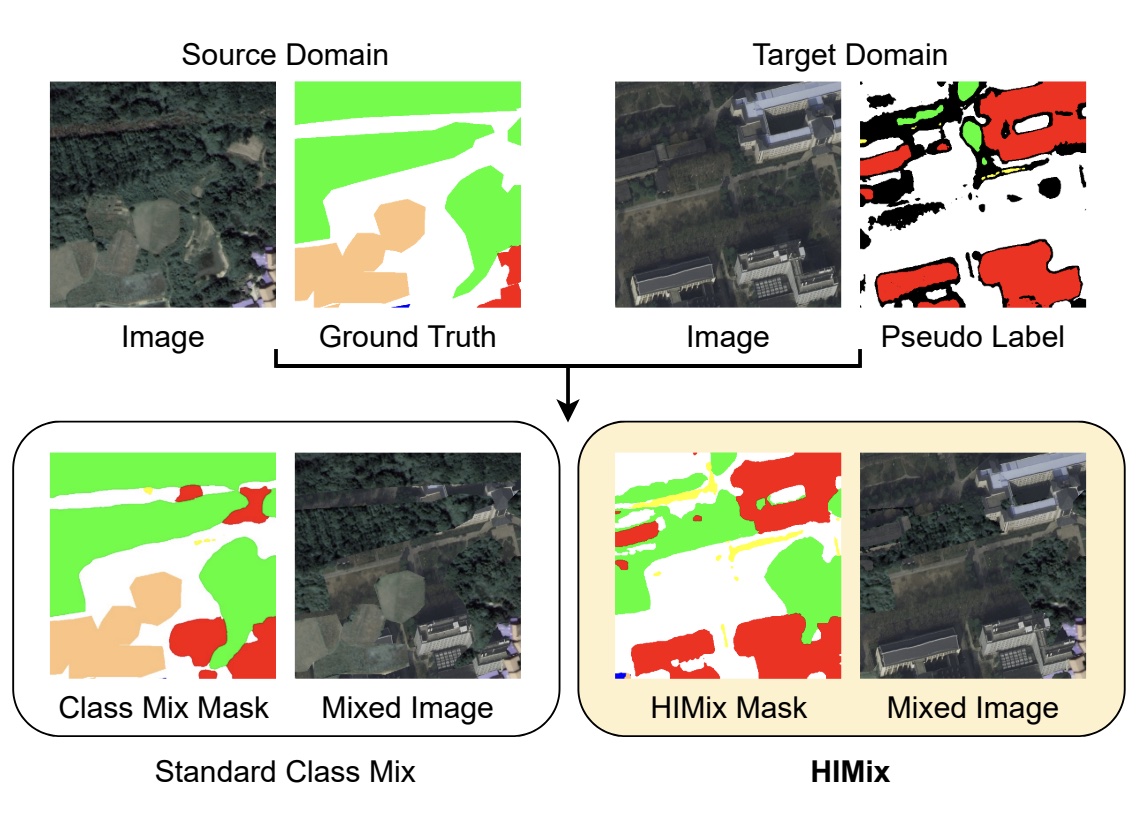 Hierarchical Instance Mixing Across Domains in Aerial SegmentationEdoardo Arnaudo, Antonio Tavera, Carlo Masone, Fabrizio Dominici, and Barbara CaputoIEEE Access, Jun 2023
Hierarchical Instance Mixing Across Domains in Aerial SegmentationEdoardo Arnaudo, Antonio Tavera, Carlo Masone, Fabrizio Dominici, and Barbara CaputoIEEE Access, Jun 2023We investigate the task of unsupervised domain adaptation in aerial semantic segmentation observing that there are some shortcomings in the class mixing strategies used by the recent state-of-the-art methods that tackle this task: 1) they do not account for the large disparity in the extension of the semantic categories that is common in the aerial setting, which causes a domain imbalance in the mixed image; 2) they do not consider that aerial scenes have a weaker structural consistency in comparison to the driving scenes for which the mixing technique was originally proposed, which causes the mixed images to have elements placed out of their natural context; 3) source model used to generate the pseudo-labels may be susceptible to perturbations across domains, which causes inconsistent predictions on the target images and can jeopardize the mixing strategy. We address these shortcomings with a novel aerial semantic segmentation framework for UDA, named HIUDA, which is composed of two main technical novelties: firstly, a new mixing strategy for aerial segmentation across domains called Hierarchical Instance Mixing (HIMix), which extracts a set of connected components from each semantic mask and mixes them according to a semantic hierarchy and secondly, a twin-head architecture in which two separate segmentation heads are fed with variations of the same images in a contrastive fashion to produce finer segmentation maps. We conduct extensive experiments on the LoveDA benchmark, where our solution outperforms the current state-of-the-art.
@article{Arnaudo-2023-hierarchical, author = {Arnaudo, Edoardo and Tavera, Antonio and Masone, Carlo and Dominici, Fabrizio and Caputo, Barbara}, journal = {IEEE Access}, title = {Hierarchical Instance Mixing Across Domains in Aerial Segmentation}, year = {2023}, volume = {11}, number = {}, pages = {13324-13333}, doi = {10.1109/ACCESS.2023.3243475}, keywords = {fine grained understanding, aerial, robust learning, spatial intelligence}, } - Conference
 Unmasking Anomalies in Road-Scene SegmentationShyam Nandan Rai, Fabio Cermelli, Dario Fontanel, Carlo Masone, and Barbara CaputoIn IEEE/CVF International Conference on Computer Vision (ICCV), Jun 2023
Unmasking Anomalies in Road-Scene SegmentationShyam Nandan Rai, Fabio Cermelli, Dario Fontanel, Carlo Masone, and Barbara CaputoIn IEEE/CVF International Conference on Computer Vision (ICCV), Jun 2023Within the top 2.3% of submitted papers, and the top 9% of accepted papers.
Anomaly segmentation is a critical task for driving applications, and it is approached traditionally as a per-pixel classification problem. However, reasoning individually about each pixel without considering their contextual semantics results in high uncertainty around the objects’ boundaries and numerous false positives. We propose a paradigm change by shifting from a per-pixel classification to a mask classification. Our mask-based method, Mask2Anomaly, demonstrates the feasibility of integrating an anomaly detection method in a mask-classification architecture. Mask2Anomaly includes several technical novelties that are designed to improve the detection of anomalies in masks: i) a global masked attention module to focus individually on the foreground and background regions; ii) a mask contrastive learning that maximizes the margin between an anomaly and known classes; and iii) a mask refinement solution to reduce false positives. Mask2Anomaly achieves new state-of-the-art results across a range of benchmarks, both in the per-pixel and component-level evaluations. In particular, Mask2Anomaly reduces the average false positives rate by 60% w.r.t. the previous state-of-the-art.
@inproceedings{Rai-2023-unmasking, author = {Rai, Shyam Nandan and Cermelli, Fabio and Fontanel, Dario and Masone, Carlo and Caputo, Barbara}, booktitle = {IEEE/CVF International Conference on Computer Vision (ICCV)}, title = {Unmasking Anomalies in Road-Scene Segmentation}, year = {2023}, volume = {}, number = {}, pages = {4014-4023}, doi = {10.1109/ICCV51070.2023.00373}, keywords = {fine grained understanding, driving, uncertainty quantification, spatial intelligence}, } - Conference
 Divide&Classify: Fine-Grained Classification for City-Wide Visual Place RecognitionGabriele Trivigno, Gabriele Berton, Juan Aragon, Barbara Caputo, and Carlo MasoneIn IEEE/CVF International Conference on Computer Vision (ICCV), Jun 2023
Divide&Classify: Fine-Grained Classification for City-Wide Visual Place RecognitionGabriele Trivigno, Gabriele Berton, Juan Aragon, Barbara Caputo, and Carlo MasoneIn IEEE/CVF International Conference on Computer Vision (ICCV), Jun 2023Visual Place recognition is commonly addressed as an image retrieval problem. However, retrieval methods are impractical to scale to large datasets, densely sampled from city-wide maps, since their dimension impact negatively on the inference time. Using approximate nearest neighbour search for retrieval helps to mitigate this issue, at the cost of a performance drop. In this paper we investigate whether we can effectively approach this task as a classification problem, thus bypassing the need for a similarity search. We find that existing classification methods for coarse, planet-wide localization are not suitable for the fine-grained and city-wide setting. This is largely due to how the dataset is split into classes, because these methods are designed to handle a sparse distribution of photos and as such do not consider the visual aliasing problem across neighbouring classes that naturally arises in dense scenarios. Thus, we propose a partitioning scheme that enables a fast and accurate inference, preserving a simple learning procedure, and a novel inference pipeline based on an ensemble of novel classifiers that uses the prototypes learned via an angular margin loss. Our method, Divide&Classify (D&C), enjoys the fast inference of classification solutions and an accuracy competitive with retrieval methods on the fine-grained, city-wide setting. Moreover, we show that D&C can be paired with existing retrieval pipelines to speed up computations by over 20 times while increasing their recall, leading to new state-of-the-art results.
@inproceedings{Trivigno-2023-divide, author = {Trivigno, Gabriele and Berton, Gabriele and Aragon, Juan and Caputo, Barbara and Masone, Carlo}, booktitle = {IEEE/CVF International Conference on Computer Vision (ICCV)}, title = {{Divide\&Classify}: Fine-Grained Classification for City-Wide Visual Place Recognition}, year = {2023}, volume = {}, number = {}, pages = {11108-11118}, doi = {10.1109/ICCV51070.2023.01023}, keywords = {localization, spatial intelligence}, } - Workshop
 The Robust Semantic Segmentation UNCV2023 Challenge ResultsXuanlong Yu, Yi Zuo, Zitao Wang, Xiaowen Zhang, Jiaxuan Zhao, Yuting Yang, Licheng Jiao, Rui Peng, Xinyi Wang, Junpei Zhang, Kexin Zhang, Fang Liu, Roberto Alcover-Couso, Juan C. SanMiguel, Marcos Escudero-Viñolo, Hanlin Tian, Kenta Matsui, Tianhao Wang, Fahmy Adan, Zhitong Gao, Xuming He, Quentin Bouniot, Hossein Moghaddam, Shyam Nandan Rai, Fabio Cermelli, Carlo Masone, Andrea Pilzer, Elisa Ricci, Andrei Bursuc, Arno Solin, Martin Trapp, Rui Li, Angela Yao, Wenlong Chen, Ivor Simpson, Neill D. F. Campbell, and Gianni FranchiIn IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Jun 2023
The Robust Semantic Segmentation UNCV2023 Challenge ResultsXuanlong Yu, Yi Zuo, Zitao Wang, Xiaowen Zhang, Jiaxuan Zhao, Yuting Yang, Licheng Jiao, Rui Peng, Xinyi Wang, Junpei Zhang, Kexin Zhang, Fang Liu, Roberto Alcover-Couso, Juan C. SanMiguel, Marcos Escudero-Viñolo, Hanlin Tian, Kenta Matsui, Tianhao Wang, Fahmy Adan, Zhitong Gao, Xuming He, Quentin Bouniot, Hossein Moghaddam, Shyam Nandan Rai, Fabio Cermelli, Carlo Masone, Andrea Pilzer, Elisa Ricci, Andrei Bursuc, Arno Solin, Martin Trapp, Rui Li, Angela Yao, Wenlong Chen, Ivor Simpson, Neill D. F. Campbell, and Gianni FranchiIn IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Jun 2023This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and venues over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
@inproceedings{Yu-2023-uncv, author = {Yu, Xuanlong and Zuo, Yi and Wang, Zitao and Zhang, Xiaowen and Zhao, Jiaxuan and Yang, Yuting and Jiao, Licheng and Peng, Rui and Wang, Xinyi and Zhang, Junpei and Zhang, Kexin and Liu, Fang and Alcover-Couso, Roberto and SanMiguel, Juan C. and Escudero-Viñolo, Marcos and Tian, Hanlin and Matsui, Kenta and Wang, Tianhao and Adan, Fahmy and Gao, Zhitong and He, Xuming and Bouniot, Quentin and Moghaddam, Hossein and Rai, Shyam Nandan and Cermelli, Fabio and Masone, Carlo and Pilzer, Andrea and Ricci, Elisa and Bursuc, Andrei and Solin, Arno and Trapp, Martin and Li, Rui and Yao, Angela and Chen, Wenlong and Simpson, Ivor and Campbell, Neill D. F. and Franchi, Gianni}, booktitle = {IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)}, title = {The Robust Semantic Segmentation UNCV2023 Challenge Results}, year = {2023}, volume = {}, number = {}, pages = {4620-4630}, doi = {10.1109/ICCVW60793.2023.00496}, keywords = {fine grained understanding, uncertainty}, } - Conference
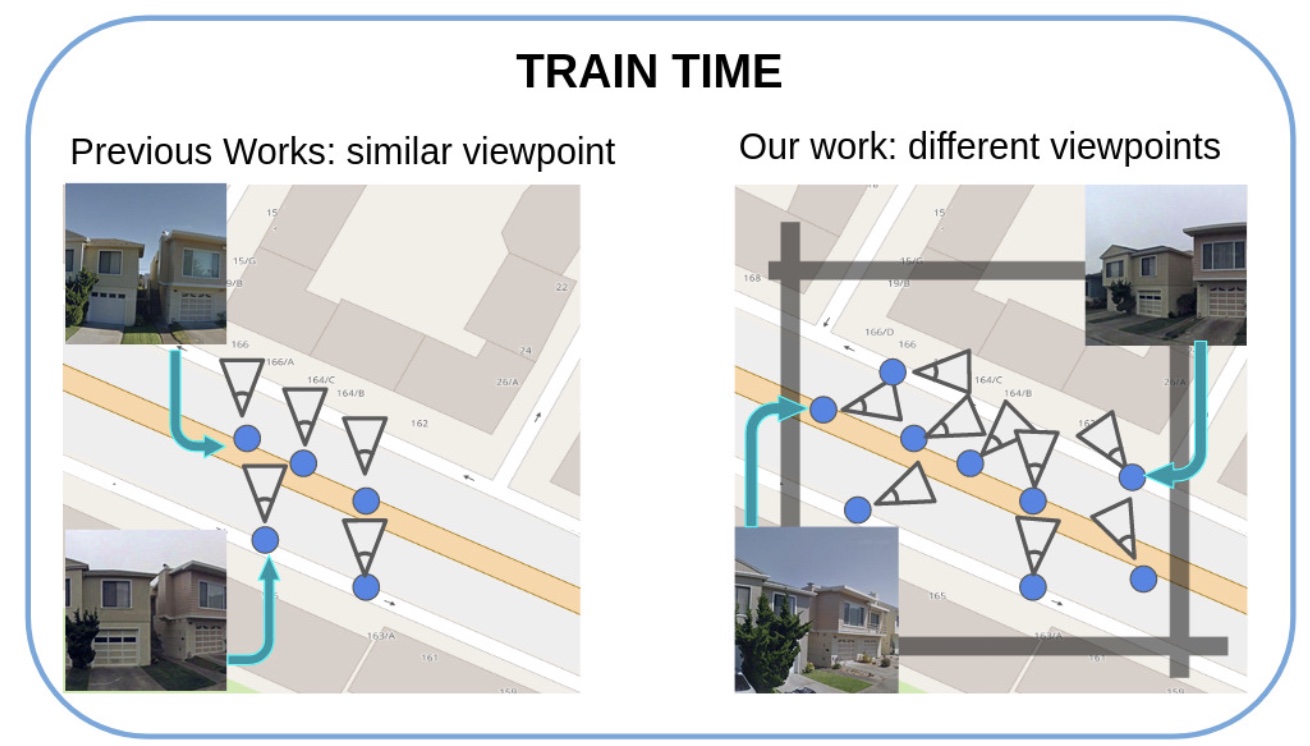 EigenPlaces: Training Viewpoint Robust Models for Visual Place RecognitionGabriele Berton, Gabriele Trivigno, Barbara Caputo, and Carlo MasoneIn IEEE/CVF International Conference on Computer Vision (ICCV), Jun 2023
EigenPlaces: Training Viewpoint Robust Models for Visual Place RecognitionGabriele Berton, Gabriele Trivigno, Barbara Caputo, and Carlo MasoneIn IEEE/CVF International Conference on Computer Vision (ICCV), Jun 2023Visual Place Recognition is a task that aims to predict the place of an image (called query) based solely on its visual features. This is typically done through image retrieval, where the query is matched to the most similar images from a large database of geotagged photos, using learned global descriptors. A major challenge in this task is recognizing places seen from different viewpoints. To overcome this limitation, we propose a new method, called EigenPlaces, to train our neural network on images from different point of views, which embeds viewpoint robustness into the learned global descriptors. The underlying idea is to cluster the training data so as to explicitly present the model with different views of the same points of interest. The selection of this points of interest is done without the need for extra supervision. We then present experiments on the most comprehensive set of datasets in literature, finding that EigenPlaces is able to outperform previous state of the art on the majority of datasets, while requiring 60% less GPU memory for training and using 50% smaller descriptors. The code and trained models for EigenPlaces are available at https://github.com/gmberton/EigenPlaces, while results with any other baseline can be computed with the codebase at https://github.com/gmberton/auto_VPR.
@inproceedings{Berton-2023-eigenplaces, author = {Berton, Gabriele and Trivigno, Gabriele and Caputo, Barbara and Masone, Carlo}, booktitle = {IEEE/CVF International Conference on Computer Vision (ICCV)}, title = {{EigenPlaces}: Training Viewpoint Robust Models for Visual Place Recognition}, year = {2023}, volume = {}, number = {}, pages = {11046-11056}, doi = {10.1109/ICCV51070.2023.01017}, keywords = {localization, spatial intelligence}, } - Workshop
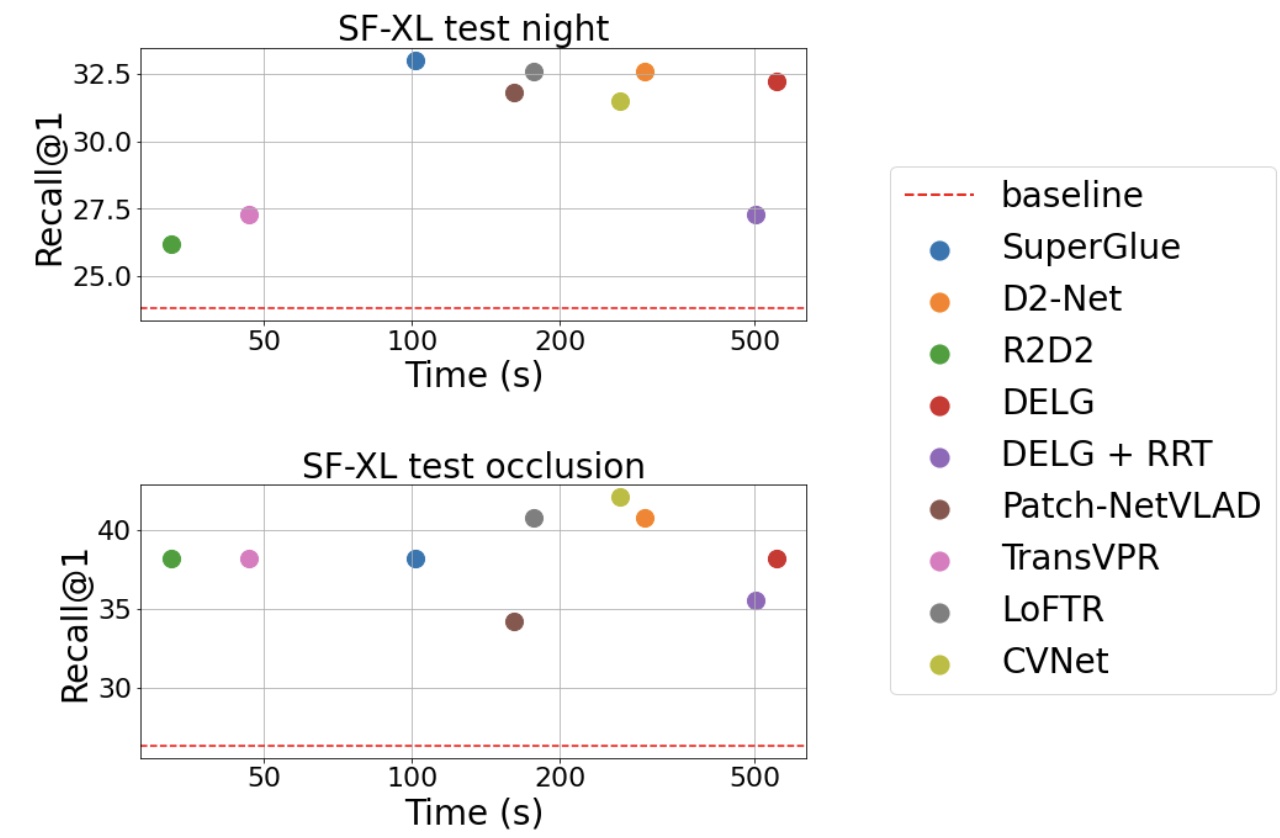 Are Local Features All You Need for Cross-Domain Visual Place Recognition?Giovanni Barbarani, Mohamad Mostafa, Hajali Bayramov, Gabriele Trivigno, Gabriele Berton, Carlo Masone, and Barbara CaputoIn IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Jun 2023
Are Local Features All You Need for Cross-Domain Visual Place Recognition?Giovanni Barbarani, Mohamad Mostafa, Hajali Bayramov, Gabriele Trivigno, Gabriele Berton, Carlo Masone, and Barbara CaputoIn IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Jun 2023Visual Place Recognition is a task that aims to predict the coordinates of an image (called query) based solely on visual clues. Most commonly, a retrieval approach is adopted, where the query is matched to the most similar images from a large database of geotagged photos, using learned global descriptors. Despite recent advances, recognizing the same place when the query comes from a significantly different distribution is still a major hurdle for state of the art retrieval methods. Examples are heavy illumination changes (e.g. night-time images) or substantial occlusions (e.g. transient objects). In this work we explore whether re-ranking methods based on spatial verification can tackle these challenges, following the intuition that local descriptors are inherently more robust than global features to domain shifts. To this end, we provide a new, comprehensive benchmark on current state of the art models. We also introduce two new demanding datasets with night and occluded queries, to be matched against a city-wide database. Code and datasets are available at https://github.com/gbarbarani/re-ranking-for-VPR.
@inproceedings{Barbarani-2023-local, author = {Barbarani, Giovanni and Mostafa, Mohamad and Bayramov, Hajali and Trivigno, Gabriele and Berton, Gabriele and Masone, Carlo and Caputo, Barbara}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}, title = {Are Local Features All You Need for Cross-Domain Visual Place Recognition?}, year = {2023}, volume = {}, number = {}, pages = {6155-6165}, doi = {10.1109/CVPRW59228.2023.00655}, }







2022
- Journal
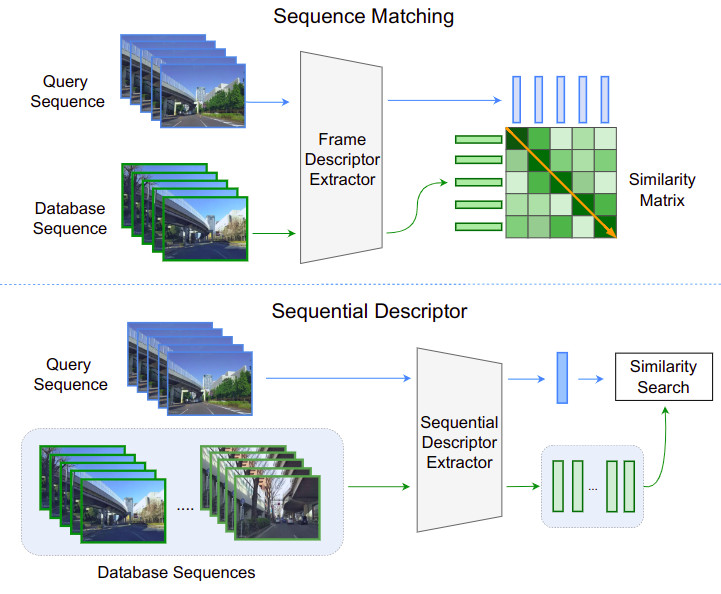 Learning Sequential Descriptors for Sequence-Based Visual Place RecognitionRiccardo Mereu, Gabriele Trivigno, Gabriele Berton, Carlo Masone, and Barbara CaputoIEEE Robotics and Automation Letters, Jun 2022
Learning Sequential Descriptors for Sequence-Based Visual Place RecognitionRiccardo Mereu, Gabriele Trivigno, Gabriele Berton, Carlo Masone, and Barbara CaputoIEEE Robotics and Automation Letters, Jun 2022In robotics, visual place recognition (VPR) is a continuous process that receives as input a video stream to produce a hypothesis of the robot’s current position within a map of known places. This work proposes a taxonomy of the architectures used to learn sequential descriptors for VPR, highlighting different mechanisms to fuse the information from the individual images. This categorization is supported by a complete benchmark of experimental results that provides evidence of the strengths and weaknesses of these different architectural choices. The analysis is not limited to existing sequential descriptors, but we extend it further to investigate the viability of Transformers instead of CNN backbones. We further propose a new ad-hoc sequence-level aggregator called SeqVLAD, which outperforms prior state of the art on different datasets. The code is available at https://github.com/vandal-vpr/vg-transformers.
@article{Mereu-2022-seqvlad, author = {Mereu, Riccardo and Trivigno, Gabriele and Berton, Gabriele and Masone, Carlo and Caputo, Barbara}, journal = {IEEE Robotics and Automation Letters}, title = {Learning Sequential Descriptors for Sequence-Based Visual Place Recognition}, year = {2022}, volume = {7}, number = {4}, pages = {10383-10390}, doi = {10.1109/LRA.2022.3194310}, keywords = {localization, spatial intelligence}, } - Journal
 Adaptive-Attentive Geolocalization From Few Queries: A Hybrid ApproachValerio Paolicelli, Gabriele Berton, Francesco Montagna, Carlo Masone, and Barbara CaputoFrontiers in Computer Science, Jun 2022
Adaptive-Attentive Geolocalization From Few Queries: A Hybrid ApproachValerio Paolicelli, Gabriele Berton, Francesco Montagna, Carlo Masone, and Barbara CaputoFrontiers in Computer Science, Jun 2022We tackle the task of cross-domain visual geo-localization, where the goal is to geo-localize a given query image against a database of geo-tagged images, in the case where the query and the database belong to different visual domains. In particular, at training time, we consider having access to only few unlabeled queries from the target domain. To adapt our deep neural network to the database distribution, we rely on a 2-fold domain adaptation technique, based on a hybrid generative-discriminative approach. To further enhance the architecture, and to ensure robustness across domains, we employ a novel attention layer that can easily be plugged into existing architectures. Through a large number of experiments, we show that this adaptive-attentive approach makes the model robust to large domain shifts, such as unseen cities or weather conditions. Finally, we propose a new large-scale dataset for cross-domain visual geo-localization, called SVOX.
@article{Paolicelli-2022-adageov2, author = {Paolicelli, Valerio and Berton, Gabriele and Montagna, Francesco and Masone, Carlo and Caputo, Barbara}, title = {Adaptive-Attentive Geolocalization From Few Queries: A Hybrid Approach}, journal = {Frontiers in Computer Science}, volume = {4}, year = {2022}, doi = {10.3389/fcomp.2022.841817}, issn = {2624-9898}, keywords = {localization, robust learning, spatial intelligence}, } - Workshop
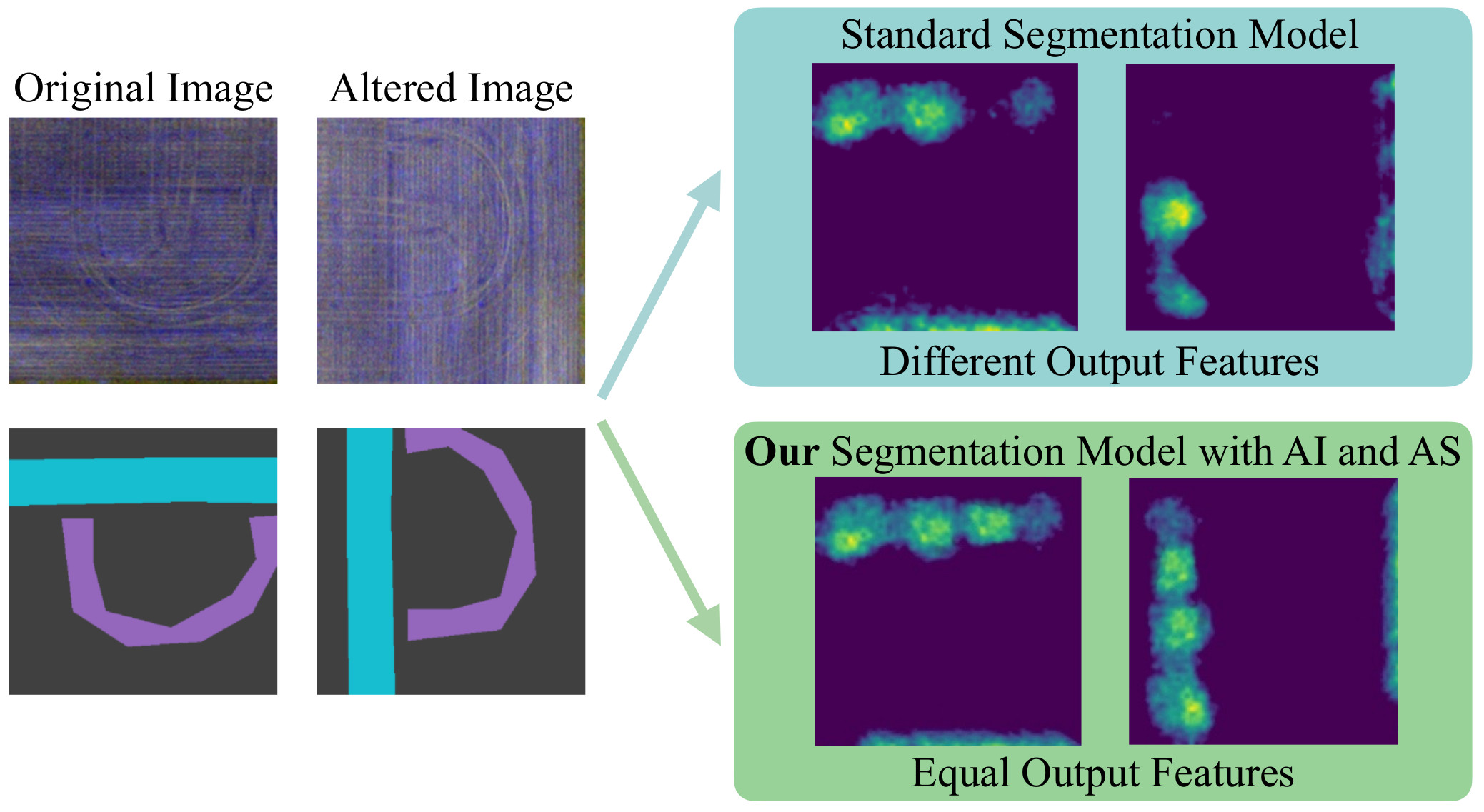 Augmentation Invariance and Adaptive Sampling in Semantic Segmentation of Agricultural Aerial ImagesA. Tavera, E. Arnaudo, C. Masone, and B. CaputoIn IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Jun 2022
Augmentation Invariance and Adaptive Sampling in Semantic Segmentation of Agricultural Aerial ImagesA. Tavera, E. Arnaudo, C. Masone, and B. CaputoIn IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Jun 2022In this paper, we investigate the problem of Semantic Segmentation for agricultural aerial imagery. We observe that the existing methods used for this task are designed without considering two characteristics of the aerial data: (i) the top-down perspective implies that the model cannot rely on a fixed semantic structure of the scene, because the same scene may be experienced with different rotations of the sensor; (ii) there can be a strong imbalance in the distribution of semantic classes because the relevant objects of the scene may appear at extremely different scales (e.g., a field of crops and a small vehicle). We propose a solution to these problems based on two ideas: (i) we use together a set of suitable augmentation and a consistency loss to guide the model to learn semantic representations that are invariant to the photometric and geometric shifts typical of the top-down perspective (Augmentation Invariance); (ii) we use a sampling method (Adaptive Sampling) that selects the training images based on a measure of pixel-wise distribution of classes and actual network confidence. With an extensive set of experiments conducted on the Agriculture-Vision dataset, we demonstrate that our proposed strategies improve the performance of the current state-of-the-art method.
@inproceedings{Tavera-2022-augmentation, author = {Tavera, A. and Arnaudo, E. and Masone, C. and Caputo, B.}, title = {Augmentation Invariance and Adaptive Sampling in Semantic Segmentation of Agricultural Aerial Images}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}, year = {2022}, pages = {1656-1665}, doi = {10.1109/CVPRW56347.2022.00172}, keywords = {fine grained understanding, aerial images, robust learning, spatial intelligence}, } - Conference
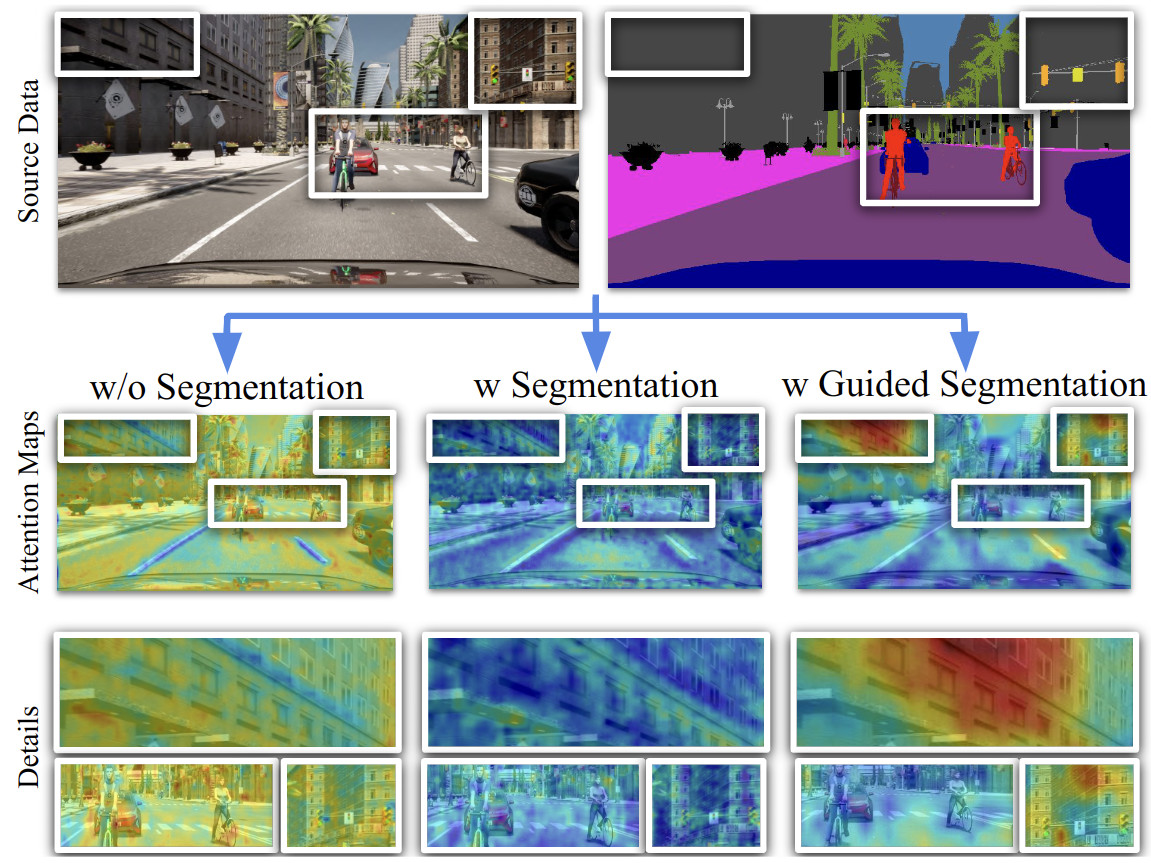 Learning Semantics for Visual Place Recognition through Multi-Scale AttentionV. Paolicelli, A. Tavera, G. Berton, C. Masone, and B. CaputoIn International Conference on Image Analysis and Processing (ICIAP), Jun 2022
Learning Semantics for Visual Place Recognition through Multi-Scale AttentionV. Paolicelli, A. Tavera, G. Berton, C. Masone, and B. CaputoIn International Conference on Image Analysis and Processing (ICIAP), Jun 2022In this paper we address the task of visual place recognition (VPR), where the goal is to retrieve the correct GPS coordinates of a given query image against a huge geotagged gallery. While recent works have shown that building descriptors incorporating semantic and appearance information is beneficial, current state-of-the-art methods opt for a top down definition of the significant semantic content. Here we present the first VPR algorithm that learns robust global embeddings from both visual appearance and semantic content of the data, with the segmentation process being dynamically guided by the recognition of places through a multi-scale attention module. Experiments on various scenarios validate this new approach and demonstrate its performance against state-of-the-art methods. Finally, we propose the first synthetic-world dataset suited for both place recognition and segmentation tasks.
@inproceedings{Paolicelli-2022-semantic, author = {Paolicelli, V. and Tavera, A. and Berton, G. and Masone, C. and Caputo, B.}, title = {Learning Semantics for Visual Place Recognition through Multi-Scale Attention}, booktitle = {International Conference on Image Analysis and Processing (ICIAP)}, editor = {Sclaroff, Stan and Distante, Cosimo and Leo, Marco and Farinella, Giovanni M. and Tombari, Federico}, year = {2022}, publisher = {Springer International Publishing}, address = {Cham}, pages = {454-466}, doi = {10.1007/978-3-031-06430-2_38}, isbn = {978-3-031-06430-2}, keywords = {localization, fine grained understanding, spatial intelligence}, } - Conference
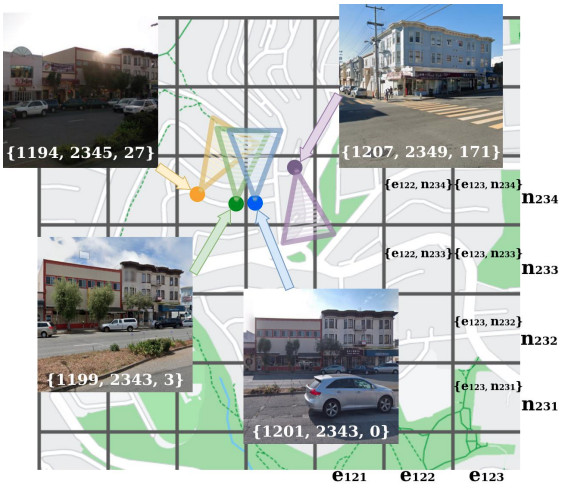 Rethinking Visual Geo-localization for Large-Scale ApplicationsG. Berton, C. Masone, and B. CaputoIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2022
Rethinking Visual Geo-localization for Large-Scale ApplicationsG. Berton, C. Masone, and B. CaputoIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2022Visual Geo-localization (VG) is the task of estimating the position where a given photo was taken by comparing it with a large database of images of known locations. To investigate how existing techniques would perform on a real-world city-wide VG application, we build San Francisco eXtra Large, a new dataset covering a whole city and providing a wide range of challenging cases, with a size 30x bigger than the previous largest dataset for visual geo-localization. We find that current methods fail to scale to such large datasets, therefore we design a new highly scalable training technique, called CosPlace, which casts the training as a classification problem avoiding the expensive mining needed by the commonly used contrastive learning. We achieve state-of-the-art performance on a wide range of datasets and find that CosPlace is robust to heavy domain changes. Moreover, we show that, compared to the previous state-of-the-art, CosPlace requires roughly 80% less GPU memory at train time, and it achieves better results with 8x smaller descriptors, paving the way for city-wide real-world visual geo-localization.
@inproceedings{Berton-2022-cosplace, author = {Berton, G. and Masone, C. and Caputo, B.}, title = {Rethinking Visual Geo-localization for Large-Scale Applications}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022}, pages = {4868-4878}, doi = {10.1109/CVPR52688.2022.00483}, keywords = {localization, spatial intelligence}, } - Conference
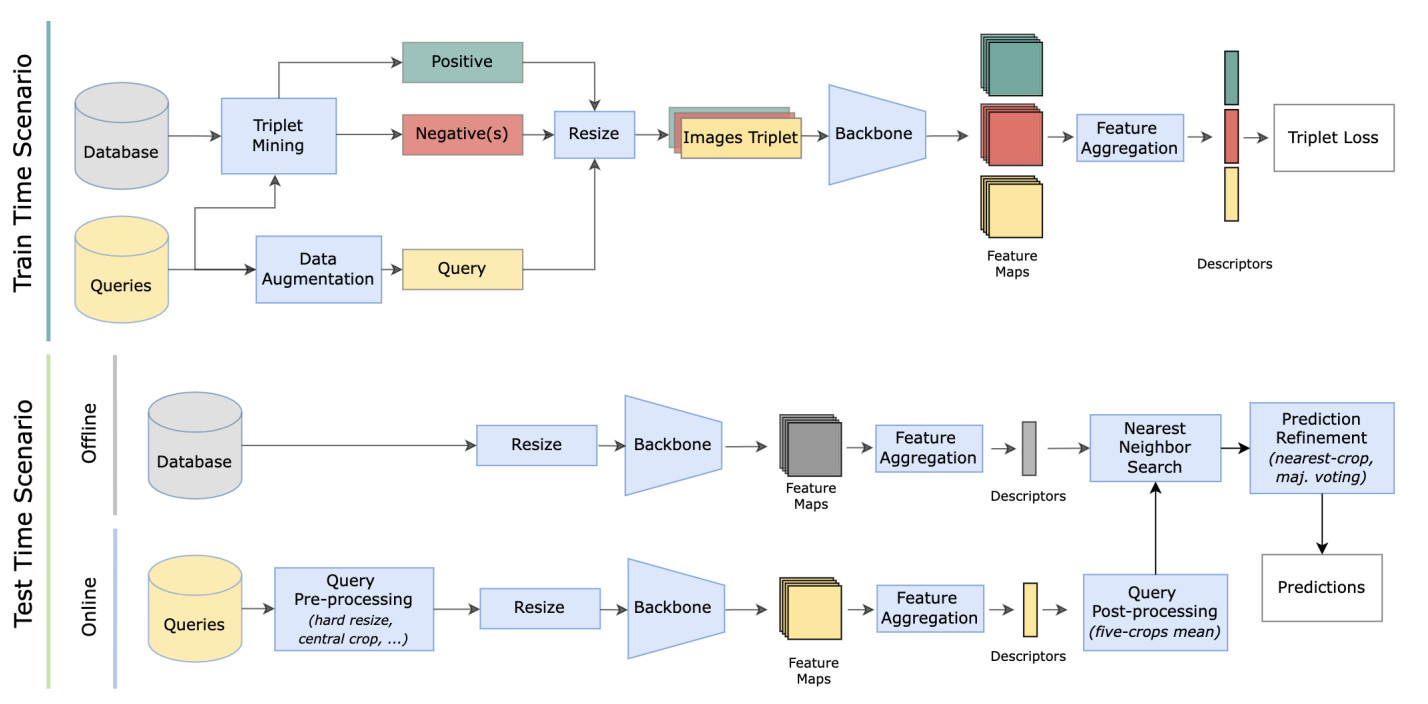 Deep Visual Geo-localization BenchmarkG. Berton, R. Mereu, G. Trivigno, C. Masone, G. Csurka, T. Sattler, and B. CaputoIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2022
Deep Visual Geo-localization BenchmarkG. Berton, R. Mereu, G. Trivigno, C. Masone, G. Csurka, T. Sattler, and B. CaputoIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2022Within the top 2% of submitted papers, and the top 7.8% of accepted papers.
In this paper, we propose a new open-source benchmarking framework for Visual Geo-localization (VG) that allows to build, train, and test a wide range of commonly used architectures, with the flexibility to change individual components of a geo-localization pipeline. The purpose of this framework is twofold: i) gaining insights into how different components and design choices in a VG pipeline impact the final results, both in terms of performance (recall@N metric) and system requirements (such as execution time and memory consumption); ii) establish a systematic evaluation protocol for comparing different methods. Using the proposed framework, we perform a large suite of experiments which provide criteria for choosing backbone, aggregation and negative mining depending on the use-case and requirements. We also assess the impact of engineering techniques like pre/post-processing, data augmentation and image resizing, showing that better performance can be obtained through somewhat simple procedures: for example, downscaling the images’ resolution to 80% can lead to similar results with a 36% savings in extraction time and dataset storage requirement.
@inproceedings{Berton-2022-benchmark, author = {Berton, G. and Mereu, R. and Trivigno, G. and Masone, C. and Csurka, G. and Sattler, T. and Caputo, B.}, title = {Deep Visual Geo-localization Benchmark}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022}, pages = {5386-5397}, doi = {10.1109/CVPR52688.2022.00532}, keywords = {localization, spatial intelligence}, } - Conference
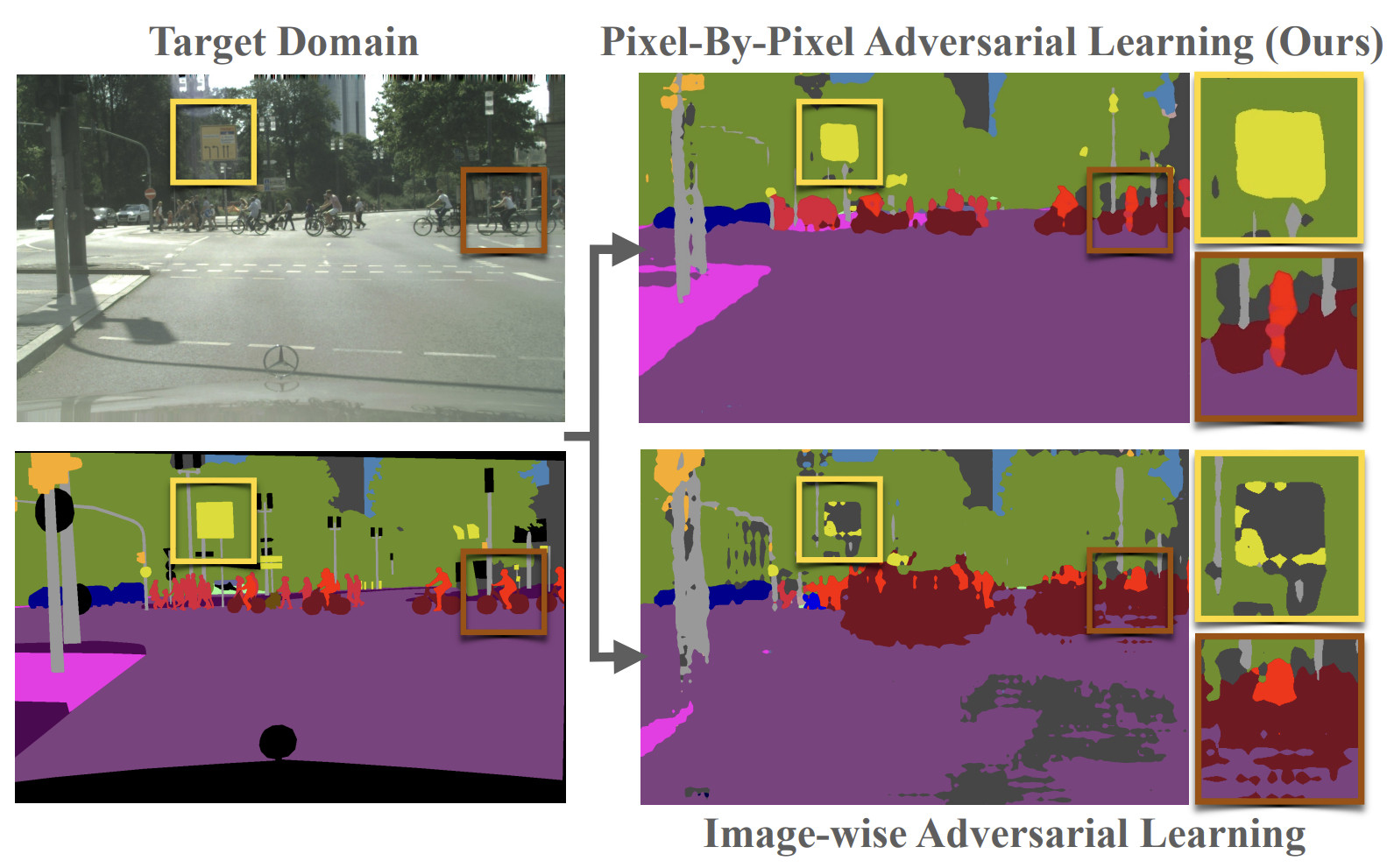 Pixel-by-Pixel Cross-Domain Alignment for Few-Shot Semantic SegmentationA. Tavera, F. Cermelli, C. Masone, and B. CaputoIn IEEE Winter Conference on Applications of Computer Vision (WACV), Jun 2022
Pixel-by-Pixel Cross-Domain Alignment for Few-Shot Semantic SegmentationA. Tavera, F. Cermelli, C. Masone, and B. CaputoIn IEEE Winter Conference on Applications of Computer Vision (WACV), Jun 2022In this paper we consider the task of semantic segmentation in autonomous driving applications. Specifically, we consider the cross-domain few-shot setting where training can use only few real-world annotated images and many annotated synthetic images. In this context, aligning the domains is made more challenging by the pixel-wise class imbalance that is intrinsic in the segmentation and that leads to ignoring the underrepresented classes and overfitting the well represented ones. We address this problem with a novel framework called Pixel-By-Pixel Cross-Domain Alignment (PixDA). We propose a novel pixel-by-pixel domain adversarial loss following three criteria: (i) align the source and the target domain for each pixel, (ii) avoid negative transfer on the correctly represented pixels, and (iii) regularize the training of infrequent classes to avoid overfitting. The pixel-wise adversarial training is assisted by a novel sample selection procedure, that handles the imbalance between source and target data, and a knowledge distillation strategy, that avoids overfitting towards the few target images. We demonstrate on standard synthetic-to-real benchmarks that PixDA outperforms previous state-of-the-art methods in (1-5)-shot settings.
@inproceedings{Tavera-2022-pixda, author = {Tavera, A. and Cermelli, F. and Masone, C. and Caputo, B.}, title = {Pixel-by-Pixel Cross-Domain Alignment for Few-Shot Semantic Segmentation}, booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)}, year = {2022}, pages = {1626-1635}, doi = {10.1109/WACV51458.2022.00202}, keywords = {fine grained understanding, driving, robust learning, spatial intelligence}, }







2021
- Conference
 Adaptive-Attentive Geolocalization from few queries: a hybrid approachG. Moreno Berton, V. Paolicelli, C. Masone, and B. CaputoIn IEEE Winter Conference on Applications of Computer Vision (WACV), Jun 2021
Adaptive-Attentive Geolocalization from few queries: a hybrid approachG. Moreno Berton, V. Paolicelli, C. Masone, and B. CaputoIn IEEE Winter Conference on Applications of Computer Vision (WACV), Jun 2021We address the task of cross-domain visual place recognition, where the goal is to geolocalize a given query image against a labeled gallery, in the case where the query and the gallery belong to different visual domains. To achieve this, we focus on building a domain robust deep network by leveraging over an attention mechanism combined with few-shot unsupervised domain adaptation techniques, where we use a small number of unlabeled target domain images to learn about the target distribution. With our method, we are able to outperform the current state of the art while using two orders of magnitude less target domain images. Finally we propose a new large-scale dataset for cross-domain visual place recognition, called SVOX.
@inproceedings{Berton-2021-adageo, author = {{Moreno Berton}, G. and Paolicelli, V. and Masone, C. and Caputo, B.}, booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)}, title = {Adaptive-Attentive Geolocalization from few queries: a hybrid approach}, year = {2021}, volume = {}, number = {}, pages = {2917-2926}, doi = {10.1109/WACV48630.2021.00296}, keyword = {localization, robust learning, spatial intelligence}, } - Conference
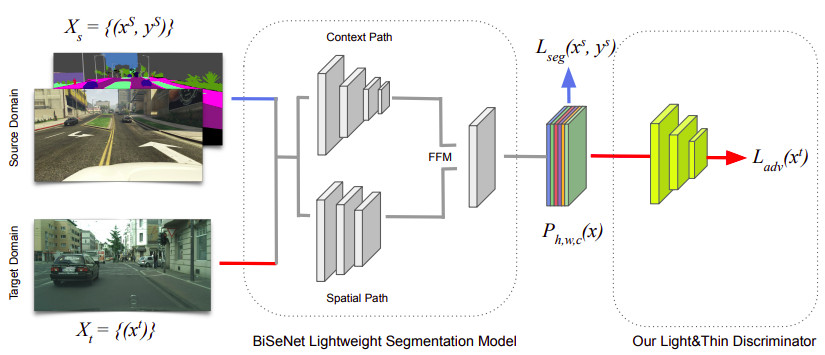 Reimagine BiSeNet for Real-Time Domain Adaptation in Semantic SegmentationA. Tavera, C. Masone, and B. CaputoIn Proceedings of the I-RIM 2021 Conference, Jun 2021
Reimagine BiSeNet for Real-Time Domain Adaptation in Semantic SegmentationA. Tavera, C. Masone, and B. CaputoIn Proceedings of the I-RIM 2021 Conference, Jun 2021Semantic segmentation models have reached remarkable performance across various tasks. However, this performance is achieved with extremely large models, using powerful computational resources and without considering training and inference time. Real-world applications, on the other hand, necessitate models with minimal memory demands, efficient inference speed, and executable with low-resources embedded devices, such as self-driving vehicles. In this paper, we look at the challenge of real-time semantic segmentation across domains, and we train a model to act appropriately on real-world data even though it was trained on a synthetic realm. We employ a new lightweight and shallow discriminator that was specifically created for this purpose. To the best of our knowledge, we are the first to present a real-time adversarial approach for assessing the domain adaption problem in semantic segmentation. We tested our framework in the two standard protocol: GTA5 to Cityscapes and SYNTHIA to Cityscapes.
@inproceedings{Tavera-2021-reimagine, author = {Tavera, A. and Masone, C. and Caputo, B.}, title = {Reimagine {BiSeNet} for Real-Time Domain Adaptation in Semantic Segmentation}, booktitle = {Proceedings of the I-RIM 2021 Conference}, year = {2021}, pages = {33-37}, doi = {10.5281/zenodo.5900517}, keywords = {fine grained understanding, spatial intelligence, robust learning}, } - Conference
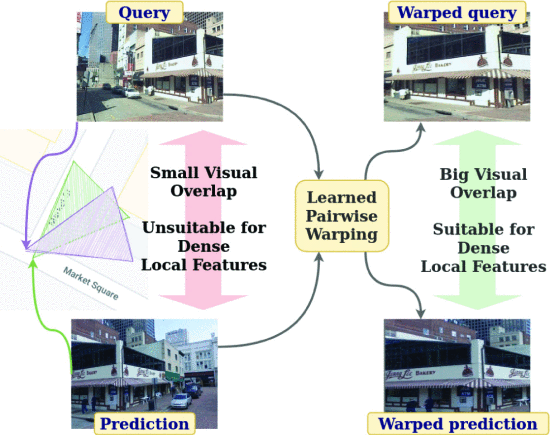 Viewpoint Invariant Dense Matching for Visual GeolocalizationG. Berton, C. Masone, V. Paolicelli, and B. CaputoIn IEEE/CVF International Conference on Computer Vision (ICCV), Jun 2021
Viewpoint Invariant Dense Matching for Visual GeolocalizationG. Berton, C. Masone, V. Paolicelli, and B. CaputoIn IEEE/CVF International Conference on Computer Vision (ICCV), Jun 2021In this paper we propose a novel method for image matching based on dense local features and tailored for visual geolocalization. Dense local features matching is robust against changes in illumination and occlusions, but not against viewpoint shifts which are a fundamental aspect of geolocalization. Our method, called GeoWarp, directly embeds invariance to viewpoint shifts in the process of extracting dense features. This is achieved via a trainable module which learns from the data an invariance that is meaningful for the task of recognizing places. We also devise a new self-supervised loss and two new weakly supervised losses to train this module using only unlabeled data and weak labels. GeoWarp is implemented efficiently as a re-ranking method that can be easily embedded into pre-existing visual geolocalization pipelines. Experimental validation on standard geolocalization benchmarks demonstrates that GeoWarp boosts the accuracy of state-of-the-art retrieval architectures.
@inproceedings{Berton-2021-viewpoint, author = {Berton, G. and Masone, C. and Paolicelli, V. and Caputo, B.}, booktitle = {IEEE/CVF International Conference on Computer Vision (ICCV)}, title = {Viewpoint Invariant Dense Matching for Visual Geolocalization}, year = {2021}, volume = {}, number = {}, pages = {12149-12158}, doi = {10.1109/ICCV48922.2021.01195}, keywords = {localization, robust learning, spatial intelligence}, } - Journal
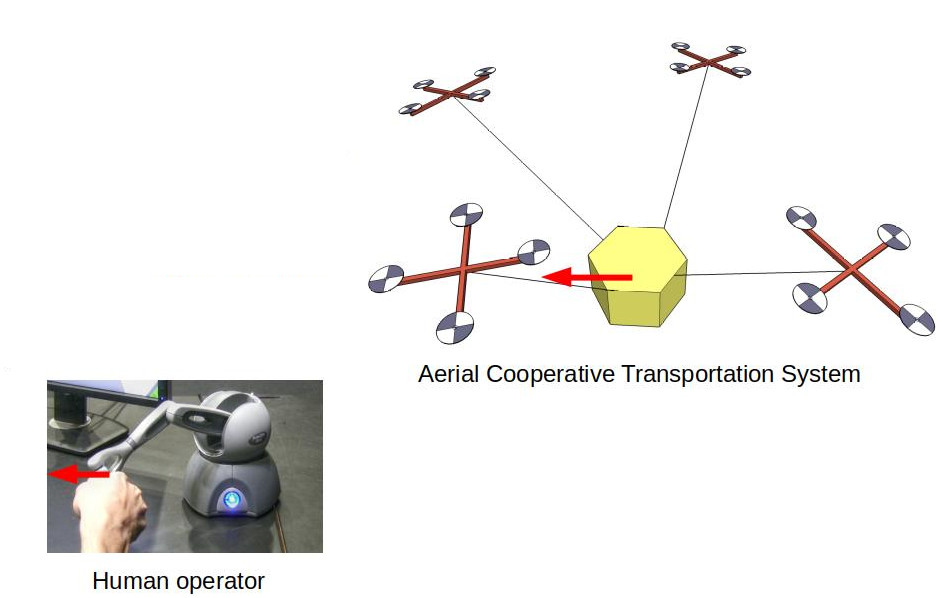 Shared Control of an Aerial Cooperative Transportation System with a Cable-suspended PayloadC. Masone, and P. StegagnoJournal of Intelligent & Robotic Systems, Jun 2021
Shared Control of an Aerial Cooperative Transportation System with a Cable-suspended PayloadC. Masone, and P. StegagnoJournal of Intelligent & Robotic Systems, Jun 2021This paper presents a novel bilateral shared framework for a cooperative aerial transportation and manipulation system composed by a team of micro aerial vehicles with a cable-suspended payload. The human operator is in charge of steering the payload and he/she can also change online the desired shape of the formation of robots. At the same time, an obstacle avoidance algorithm is in charge of avoiding collisions with the static environment. The signals from the user and from the obstacle avoidance are blended together in the trajectory generation module, by means of a tracking controller and a filter called dynamic input boundary (DIB). The DIB filters out the directions of motions that would bring the system too close to singularities, according to a suitable metric. The loop with the user is finally closed with a force feedback that is informative of the mismatch between the operator’s commands and the trajectory of the payload. This feedback intuitively increases the user’s awareness of obstacles or configurations of the system that are close to singularities. The proposed framework is validated by means of realistic hardware-in-the-loop simulations with a person operating the system via a force-feedback haptic interface.
@article{Masone-2021-sharedtransport, author = {Masone, C. and Stegagno, P.}, journal = {Journal of Intelligent & Robotic Systems}, title = {Shared Control of an Aerial Cooperative Transportation System with a Cable-suspended Payload}, year = {2021}, volume = {103}, number = {40}, pages = {}, doi = {10.1007/s10846-021-01457-4}, keywords = {shared control, aerial robotics, aerial cable robot}, } - Journal
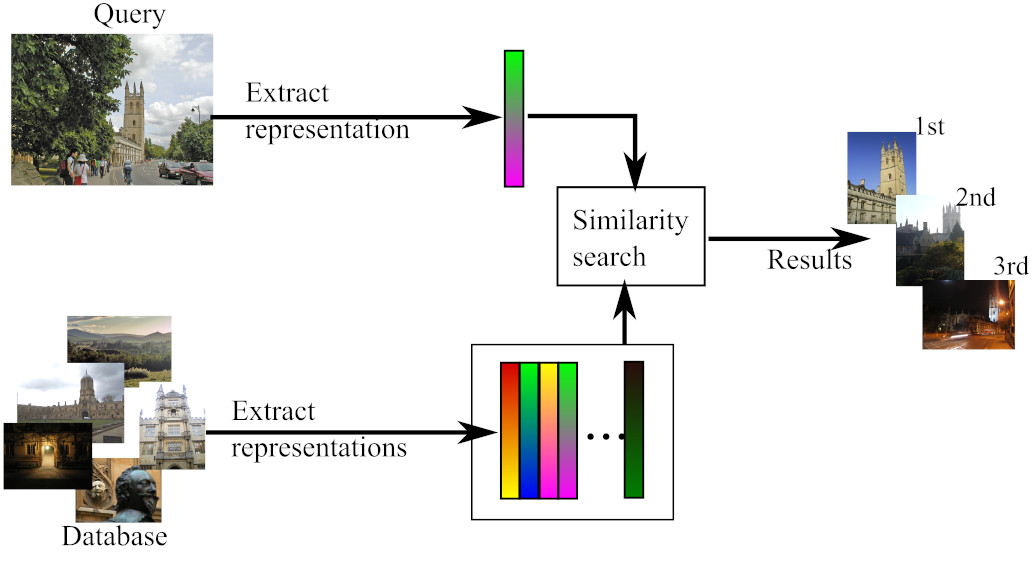 A Survey on Deep Visual Place RecognitionC. Masone, and B. CaputoIEEE Access, Jun 2021
A Survey on Deep Visual Place RecognitionC. Masone, and B. CaputoIEEE Access, Jun 2021In recent years visual place recognition (VPR), i.e., the problem of recognizing the location of images, has received considerable attention from multiple research communities, spanning from computer vision to robotics and even machine learning. This interest is fueled on one hand by the relevance that visual place recognition holds for many applications and on the other hand by the unsolved challenge of making these methods perform reliably in different conditions and environments. This paper presents a survey of the state-of-the-art of research on visual place recognition, focusing on how it has been shaped by the recent advances in deep learning. We start discussing the image representations used in this task and how they have evolved from using hand-crafted to deep-learned features. We further review how metric learning techniques are used to get more discriminative representations, as well as techniques for dealing with occlusions, distractors, and shifts in the visual domain of the images. The survey also provides an overview of the specific solutions that have been proposed for applications in robotics and with aerial imagery. Finally the survey provides a summary of datasets that are used in visual place recognition, highlighting their different characteristics.
@article{Masone-2021-survey, author = {Masone, C. and Caputo, B.}, journal = {IEEE Access}, title = {A Survey on Deep Visual Place Recognition}, year = {2021}, volume = {9}, number = {}, pages = {19516-19547}, doi = {10.1109/ACCESS.2021.3054937}, keywords = {localization, spatial intelligence}, }





2020
- Journal
 IDDA: A Large-Scale Multi-Domain Dataset for Autonomous DrivingE. Alberti, A. Tavera, C. Masone, and B. CaputoIEEE Robotics and Automation Letters, Jun 2020
IDDA: A Large-Scale Multi-Domain Dataset for Autonomous DrivingE. Alberti, A. Tavera, C. Masone, and B. CaputoIEEE Robotics and Automation Letters, Jun 2020Semantic segmentation is key in autonomous driving. Using deep visual learning architectures is not trivial in this context, because of the challenges in creating suitable large scale annotated datasets. This issue has been traditionally circumvented through the use of synthetic datasets, that have become a popular resource in this field. They have been released with the need to develop semantic segmentation algorithms able to close the visual domain shift between the training and test data. Although exacerbated by the use of artificial data, the problem is extremely relevant in this field even when training on real data. Indeed, weather conditions, viewpoint changes and variations in the city appearances can vary considerably from car to car, and even at test time for a single, specific vehicle. How to deal with domain adaptation in semantic segmentation, and how to leverage effectively several different data distributions (source domains) are important research questions in this field. To support work in this direction, this letter contributes a new large scale, synthetic dataset for semantic segmentation with more than 100 different source visual domains. The dataset has been created to explicitly address the challenges of domain shift between training and test data in various weather and view point conditions, in seven different city types. Extensive benchmark experiments assess the dataset, showcasing open challenges for the current state of the art.
@article{Alberti-2020-idda, author = {Alberti, E. and Tavera, A. and Masone, C. and Caputo, B.}, journal = {IEEE Robotics and Automation Letters}, title = {IDDA: A Large-Scale Multi-Domain Dataset for Autonomous Driving}, year = {2020}, volume = {5}, number = {4}, pages = {5526-5533}, doi = {10.1109/LRA.2020.3009075}, keywords = {fine grained understanding, driving, robust learning, spatial intelligence}, }

2018
- Conference
 Application of a Differentiator-Based Adaptive Super-Twisting Controller for a Redundant Cable-Driven Parallel RobotC. Schenk, C. Masone, A. Pott, and Heinrich H. BülthoffIn Cable-Driven Parallel Robots, Jun 2018
Application of a Differentiator-Based Adaptive Super-Twisting Controller for a Redundant Cable-Driven Parallel RobotC. Schenk, C. Masone, A. Pott, and Heinrich H. BülthoffIn Cable-Driven Parallel Robots, Jun 2018In this paper we present preliminary, experimental results of an Adaptive Super-Twisting Sliding-Mode Controller with time-varying gains for redundant Cable-Driven Parallel Robots. The sliding-mode controller is paired with a feed-forward action based on dynamics inversion. An exact sliding-mode differentiator is implemented to retrieve the velocity of the end-effector using only encoder measurements with the properties of finite-time convergence, robustness against perturbations and noise filtering. The platform used to validate the controller is a robot with eight cables and six degrees of freedom powered by 940W compact servo drives. The proposed experiment demonstrates the performance of the controller, finite-time convergence and robustness in tracking a trajectory while subject to external disturbances up to approximately 400% the mass of the end-effector.
@inproceedings{Schenk-2018-supertwisting, author = {Schenk, C. and Masone, C. and Pott, A. and Bülthoff, Heinrich H.}, editor = {Gosselin, C. and Cardou, P. and Bruckmann, T. and Pott, A.}, title = {Application of a Differentiator-Based Adaptive Super-Twisting Controller for a Redundant Cable-Driven Parallel Robot}, booktitle = {Cable-Driven Parallel Robots}, year = {2018}, publisher = {Springer International Publishing}, address = {Cham}, pages = {254-267}, doi = {10.1007/978-3-319-61431-1_22}, keywords = {cable robot,robust control, CableRobot simulator}, } - Journal
 Shared planning and control for mobile robots with integral haptic feedbackC. Masone, M. Mohammadi, P. Robuffo Giordano, and A. FranchiThe International Journal of Robotics Research, Jun 2018
Shared planning and control for mobile robots with integral haptic feedbackC. Masone, M. Mohammadi, P. Robuffo Giordano, and A. FranchiThe International Journal of Robotics Research, Jun 2018This paper presents a novel bilateral shared framework for online trajectory generation for mobile robots. The robot navigates along a dynamic path, represented as a B-spline, whose parameters are jointly controlled by a human supervisor and an autonomous algorithm. The human steers the reference (ideal) path by acting on the path parameters that are also affected, at the same time, by the autonomous algorithm to ensure: (i) collision avoidance, (ii) path regularity, and (iii) proximity to some points of interest. These goals are achieved by combining a gradient descent-like control action with an automatic algorithm that re-initializes the traveled path (replanning) in cluttered environments to mitigate the effects of local minima. The control actions of both the human and the autonomous algorithm are fused via a filter that preserves a set of local geometrical properties of the path to ease the tracking task of the mobile robot. The bilateral component of the interaction is implemented via a force feedback that accounts for both human and autonomous control actions along the whole path, thus providing information about the mismatch between the reference and traveled path in an integral sense. The proposed framework is validated by means of realistic simulations and actual experiments deploying a quadrotor unmanned aerial vehicle (UAV) supervised by a human operator acting via a force-feedback haptic interface. Finally, a user study is presented to validate the effectiveness of the proposed framework and the usefulness of the provided force cues.
@article{Masone-2018-sharedplanning, author = {Masone, C. and Mohammadi, M. and {Robuffo Giordano}, P. and Franchi, A.}, title = {Shared planning and control for mobile robots with integral haptic feedback}, journal = {The International Journal of Robotics Research}, volume = {37}, number = {11}, pages = {1395-1420}, year = {2018}, doi = {10.1177/0278364918802006}, keywords = {shared control, aerial robotics}, }


2016
- Conference
 The CableRobot simulator large scale motion platform based on cable robot technologyP. Miermeister, M. Lächele, R. Boss, C. Masone, C. Schenk, J. Tesch, M. Kerger, H. Teufel, A. Pott, and H. H. BülthoffIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2016
The CableRobot simulator large scale motion platform based on cable robot technologyP. Miermeister, M. Lächele, R. Boss, C. Masone, C. Schenk, J. Tesch, M. Kerger, H. Teufel, A. Pott, and H. H. BülthoffIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2016Winner of the IROS JTCF Novel Technology Paper Award for Amusement Culture
This paper introduces the CableRobot simulator, which was developed at the Max Planck Institute for Biological Cybernetics in cooperation with the Fraunhofer Institute for Manufacturing Engineering and Automation IPA. The simulator is a completely novel approach to the design of motion simulation platforms in so far as it uses cables and winches for actuation instead of rigid links known from hexapod simulators. This approach allows to reduce the actuated mass, scale up the workspace significantly, and provides great flexibility to switch between system configurations in which the robot can be operated. The simulator will be used for studies in the field of human perception research and virtual reality applications. The paper discusses some of the issues arising from the usage of cables and provides a system overview regarding kinematics and system dynamics as well as giving a brief introduction into possible application use cases.
@inproceedings{Miermeister-2016-cablerobot, author = {Miermeister, P. and Lächele, M. and Boss, R. and Masone, C. and Schenk, C. and Tesch, J. and Kerger, M. and Teufel, H. and Pott, A. and Bülthoff, H. H.}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, title = {The {CableRobot} simulator large scale motion platform based on cable robot technology}, year = {2016}, volume = {}, number = {}, pages = {3024-3029}, doi = {10.1109/IROS.2016.7759468}, keywords = {cable robot, CableRobot simulator}, } - Conference
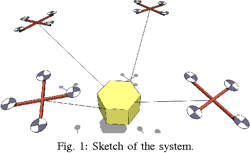 Cooperative transportation of a payload using quadrotors: A reconfigurable cable-driven parallel robotC. Masone, H. H. Bülthoff, and P. StegagnoIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2016
Cooperative transportation of a payload using quadrotors: A reconfigurable cable-driven parallel robotC. Masone, H. H. Bülthoff, and P. StegagnoIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2016This paper addresses the problem of cooperative aerial transportation of an object using a team of quadrotors. The approach presented to solve this problem accounts for the full dynamics of the system and it is inspired by the literature on reconfigurable cable-driven parallel robots (RCDPR). Using the modelling convention of RCDPR it is derived a direct relation between the motion of the quadrotors and the motion of the payload. This relation makes explicit the available internal motion of the system, which can be used to automatically achieve additional tasks. The proposed method does not require to specify a priory the forces in the cables and uses a tension distribution algorithm to optimally distribute them among the robots. The presented framework is also suitable for online teleoperation. Physical simulations with a human-in-the-loop validate the proposed approach.
@inproceedings{Masone-2016-cooperative, author = {Masone, C. and Bülthoff, H. H. and Stegagno, P.}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, title = {Cooperative transportation of a payload using quadrotors: A reconfigurable cable-driven parallel robot}, year = {2016}, volume = {}, number = {}, pages = {1623-1630}, doi = {10.1109/IROS.2016.7759262}, keywords = {cable robot, aerial robotics, aerial cable robot}, } - Conference
 Modeling and analysis of cable vibrations for a cable-driven parallel robotC. Schenk, C. Masone, P. Miermeister, and H. H. BülthoffIn IEEE International Conference on Information and Automation (ICIA), Jun 2016
Modeling and analysis of cable vibrations for a cable-driven parallel robotC. Schenk, C. Masone, P. Miermeister, and H. H. BülthoffIn IEEE International Conference on Information and Automation (ICIA), Jun 2016Best Paper award Finalist at the 2016 IEEE International Conference on Information and Automation (ICIA)
In this paper we study if approximated linear models are accurate enough to predict the vibrations of a cable of a Cable-Driven Parallel Robot (CDPR) for different pretension levels. In two experiments we investigated the damping of a thick steel cable from the Cablerobot simulator and measured the motion of the cable when a sinusoidal force is applied at one end of the cable. Using this setup and power spectral density analysis we measured the natural frequencies of the cable and compared these results to the frequencies predicted by two linear models: i) the linearization of partial differential equations of motion for a distributed cable, and ii) the discretization of the cable using a finite elements model. This comparison provides remarkable insights into the limits of approximated linear models as well as important properties of vibrating cables used in CDPR.
@inproceedings{Schenk-2016-vibrations, author = {Schenk, C. and Masone, C. and Miermeister, P. and Bülthoff, H. H.}, booktitle = {IEEE International Conference on Information and Automation (ICIA)}, title = {Modeling and analysis of cable vibrations for a cable-driven parallel robot}, year = {2016}, volume = {}, number = {}, pages = {454-461}, doi = {10.1109/ICInfA.2016.7831867}, keywords = {cable robot, CableRobot simulator}, } - Conference
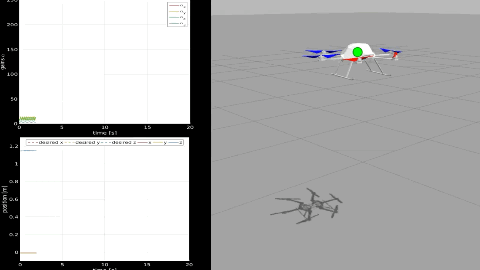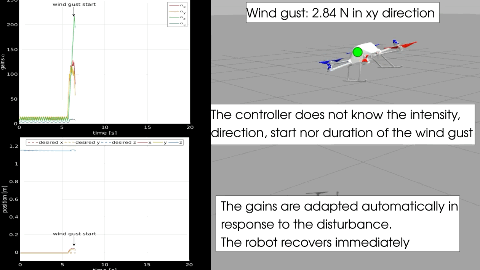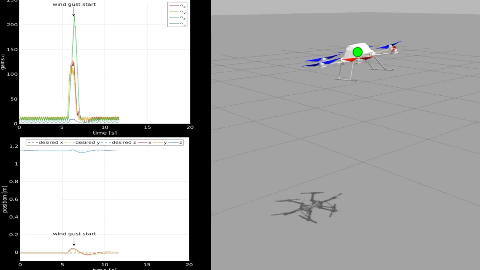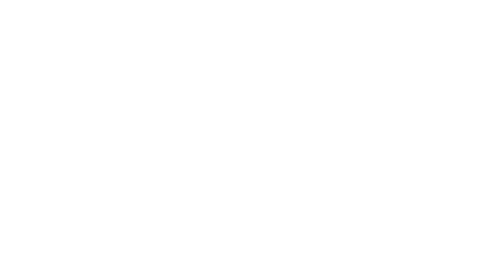 Adaptive Super Twisting Controller for a quadrotor UAVS. Rajappa, C. Masone, H. H. Bülthoff, and P. StegagnoIn IEEE International Conference on Robotics and Automation (ICRA), Jun 2016
Adaptive Super Twisting Controller for a quadrotor UAVS. Rajappa, C. Masone, H. H. Bülthoff, and P. StegagnoIn IEEE International Conference on Robotics and Automation (ICRA), Jun 2016In this paper we present a robust quadrotor controller for tracking a reference trajectory in presence of uncertainties and disturbances. A Super Twisting controller is implemented using the recently proposed gain adaptation law [1], [2], which has the advantage of not requiring the knowledge of the upper bound of the lumped uncertainties. The controller design is based on the regular form of the quadrotor dynamics, without separation in two nested control loops for position and attitude. The controller is further extended by a feedforward dynamic inversion control that reduces the effort of the sliding mode controller. The higher order quadrotor dynamic model and proposed controller are validated using a SimMechanics physical simulation with initial error, parameter uncertainties, noisy measurements and external perturbations.
@inproceedings{Rajappa-2016-supertwisting, author = {Rajappa, S. and Masone, C. and Bülthoff, H. H. and Stegagno, P.}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, title = {Adaptive Super Twisting Controller for a quadrotor {UAV}}, year = {2016}, volume = {}, number = {}, pages = {2971-2977}, doi = {10.1109/ICRA.2016.7487462}, keywords = {robust control, aerial robotics}, }




2015
- Conference
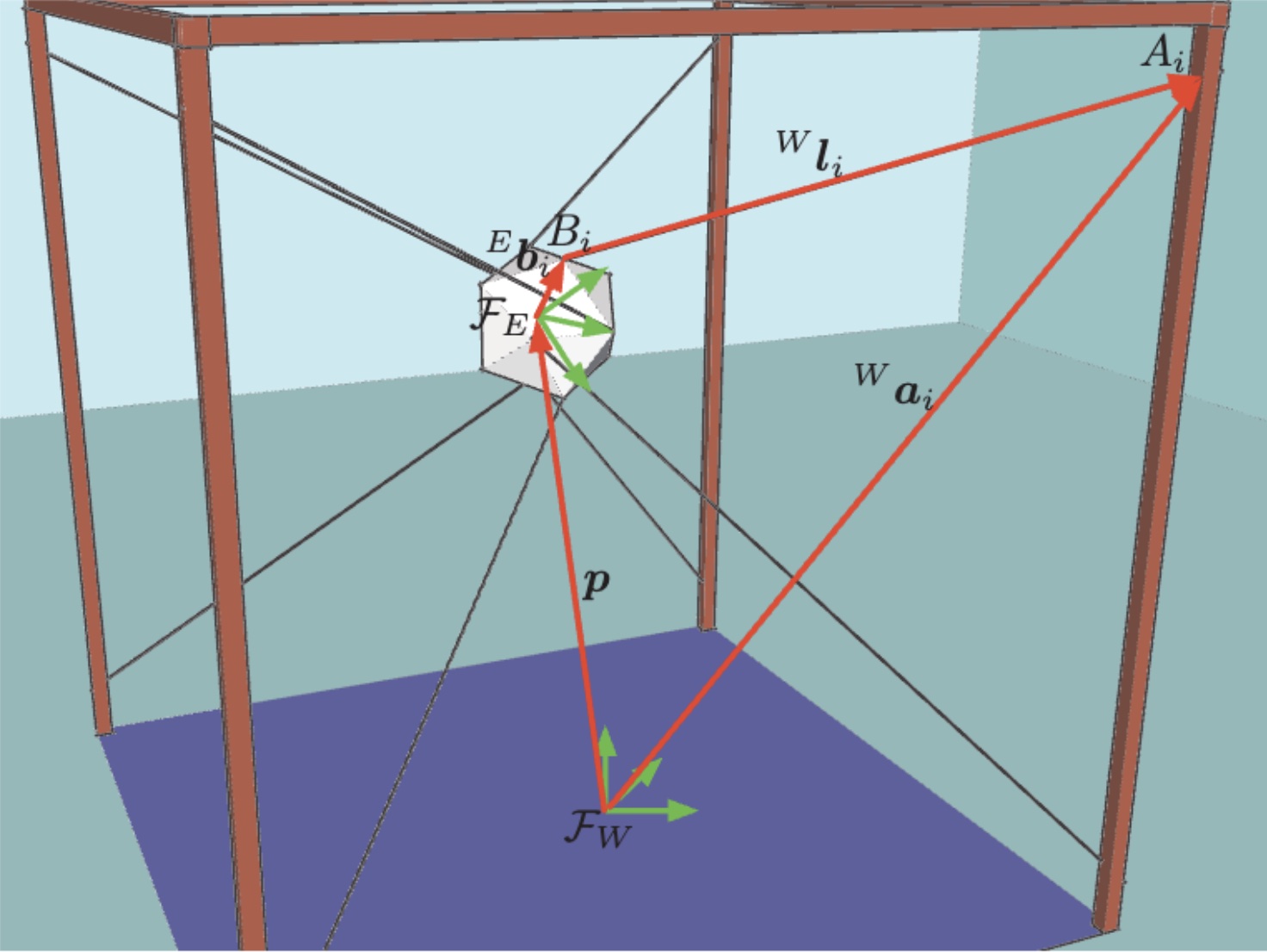 Robust adaptive sliding mode control of a redundant cable driven parallel robotC. Schenk, H. H. Bülthoff, and C. MasoneIn 2015 19th International Conference on System Theory, Control and Computing (ICSTCC), Jun 2015
Robust adaptive sliding mode control of a redundant cable driven parallel robotC. Schenk, H. H. Bülthoff, and C. MasoneIn 2015 19th International Conference on System Theory, Control and Computing (ICSTCC), Jun 2015In this paper we consider the application problem of a redundant cable-driven parallel robot, tracking a reference trajectory in presence of uncertainties and disturbances. A Super Twisting controller is implemented using a recently proposed gains adaptation law [1], thus not requiring the knowledge of the upper bound of the lumped uncertainties. The controller is extended by a feedforward dynamic inversion control that reduces the effort of the sliding mode controller. Compared to a recently developed Adaptive Terminal Sliding Mode Controller for cable-driven parallel robots [2], the proposed controller manages to achieve lower tracking errors and less chattering in the actuation forces even in presence of perturbations. The system is implemented and tested in simulation using a model of a large redundant cable-driven robot and assuming noisy measurements. Simulations show the effectiveness of the proposed method.
@inproceedings{Schenk-2015-sliding, author = {Schenk, C. and Bülthoff, H. H. and Masone, C.}, booktitle = {2015 19th International Conference on System Theory, Control and Computing (ICSTCC)}, title = {Robust adaptive sliding mode control of a redundant cable driven parallel robot}, year = {2015}, volume = {}, number = {}, pages = {427-434}, doi = {10.1109/ICSTCC.2015.7321331}, }

2014
- Conference
 Semi-autonomous trajectory generation for mobile robots with integral haptic shared controlC. Masone, P. Robuffo Giordano, H. H. Bülthoff, and A. FranchiIn IEEE International Conference on Robotics and Automation (ICRA), Jun 2014
Semi-autonomous trajectory generation for mobile robots with integral haptic shared controlC. Masone, P. Robuffo Giordano, H. H. Bülthoff, and A. FranchiIn IEEE International Conference on Robotics and Automation (ICRA), Jun 2014A new framework for semi-autonomous path planning for mobile robots that extends the classical paradigm of bilateral shared control is presented. The path is represented as a B-spline and the human operator can modify its shape by controlling the motion of a finite number of control points. An autonomous algorithm corrects in real time the human directives in order to facilitate path tracking for the mobile robot and ensures i) collision avoidance, ii) path regularity, and iii) attraction to nearby points of interest. A haptic feedback algorithm processes both human’s and autonomous control terms, and their integrals, to provide an information of the mismatch between the path specified by the operator and the one corrected by the autonomous algorithm. The framework is validated with extensive experiments using a quadrotor UAV and a human in the loop with two haptic interfaces.
@inproceedings{Masone-2014-trajectory, author = {Masone, C. and {Robuffo Giordano}, P. and Bülthoff, H. H. and Franchi, A.}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, title = {Semi-autonomous trajectory generation for mobile robots with integral haptic shared control}, year = {2014}, volume = {}, number = {}, pages = {6468-6475}, doi = {10.1109/ICRA.2014.6907814}, keywords = {shared control, aerial robotics}, }

2012
- Journal
 Modeling and Control of UAV Bearing Formations with Bilateral High-level SteeringA. Franchi, C. Masone, V. Grabe, M. Ryll, H. H. Bülthoff, and P. Robuffo GiordanoThe International Journal of Robotics Research, Jun 2012
Modeling and Control of UAV Bearing Formations with Bilateral High-level SteeringA. Franchi, C. Masone, V. Grabe, M. Ryll, H. H. Bülthoff, and P. Robuffo GiordanoThe International Journal of Robotics Research, Jun 2012In this paper we address the problem of controlling the motion of a group of unmanned aerial vehicles (UAVs) bound to keep a formation defined in terms of only relative angles (i.e. a bearing formation). This problem can naturally arise within the context of several multi-robot applications such as, e.g. exploration, coverage, and surveillance. First, we introduce and thoroughly analyze the concept and properties of bearing formations, and provide a class of minimally linear sets of bearings sufficient to uniquely define such formations. We then propose a bearing-only formation controller requiring only bearing measurements, converging almost globally, and maintaining bounded inter-agent distances despite the lack of direct metric information.The controller still leaves the possibility of imposing group motions tangent to the current bearing formation. These can be either autonomously chosen by the robots because of any additional task (e.g. exploration), or exploited by an assisting human co-operator. For this latter ’human-in-the-loop’ case, we propose a multi-master/multi-slave bilateral shared control system providing the co-operator with some suitable force cues informative of the UAV performance. The proposed theoretical framework is extensively validated by means of simulations and experiments with quadrotor UAVs equipped with onboard cameras. Practical limitations, e.g. limited field-of-view, are also considered.
@article{Franchi-2012-bearing, author = {Franchi, A. and Masone, C. and Grabe, V. and Ryll, M. and Bülthoff, H. H. and {Robuffo Giordano}, P.}, title = {Modeling and Control of {UAV} Bearing Formations with Bilateral High-level Steering}, journal = {The International Journal of Robotics Research}, volume = {31}, number = {12}, pages = {1504-1525}, year = {2012}, doi = {10.1177/0278364912462493}, keywords = {shared control, aerial robotics}, } - Conference
 Interactive planning of persistent trajectories for human-assisted navigation of mobile robotsC. Masone, A. Franchi, H. H. Bülthoff, and P. Robuffo GiordanoIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2012
Interactive planning of persistent trajectories for human-assisted navigation of mobile robotsC. Masone, A. Franchi, H. H. Bülthoff, and P. Robuffo GiordanoIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2012This work extends the framework of bilateral shared control of mobile robots with the aim of increasing the robot autonomy and decreasing the operator commitment. We consider persistent autonomous behaviors where a cyclic motion must be executed by the robot. The human operator is in charge of modifying online some geometric properties of the desired path. This is then autonomously processed by the robot in order to produce an actual path guaranteeing: i) tracking feasibility, ii) collision avoidance with obstacles, iii) closeness to the desired path set by the human operator, and iv) proximity to some points of interest. A force feedback is implemented to inform the human operator of the global deformation of the path rather than using the classical mismatch between desired and executed motion commands. Physically-based simulations, with human/hardware-in-the-loop and a quadrotor UAV as robotic platform, demonstrate the feasibility of the method.
@inproceedings{Masone-2012-interactive, author = {Masone, C. and Franchi, A. and Bülthoff, H. H. and {Robuffo Giordano}, P.}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, title = {Interactive planning of persistent trajectories for human-assisted navigation of mobile robots}, year = {2012}, volume = {}, number = {}, pages = {2641-2648}, doi = {10.1109/IROS.2012.6386171}, keywords = {shared control, aerial robotics} } - Conference
 Roll rate thresholds and perceived realism in driving simulationA. Nesti, C. Masone, M. Barnett-Cowan, P. Robuffo Giordano, H. H. Bülthoff, and P. PrettoIn Driving Simulation Conference, Jun 2012
Roll rate thresholds and perceived realism in driving simulationA. Nesti, C. Masone, M. Barnett-Cowan, P. Robuffo Giordano, H. H. Bülthoff, and P. PrettoIn Driving Simulation Conference, Jun 2012Due to limited operational space, in dynamic driving simulators it is common practice to implement motion cueing algorithms that tilt the simulator cabin to reproduce sustained accelerations. In order to avoid conflicting inertial cues, the tilt rate is kept below drivers’ perceptual thresholds, which are typically derived from the results of classical vestibular research where additional sensory cues to self-motion are removed. Here we conduct two experiments in order to assess whether higher tilt limits can be employed to expand the user’s perceptual workspace of dynamic driving simulators. In the first experiment we measure detection thresholds for roll in conditions that closely resemble typical driving. In the second experiment we measure drivers’ perceived realism in slalom driving for sub-, near- and supra-threshold roll rates. Results show that detection threshold for roll in an active driving task is remarkably higher than the limits currently used in motion cueing algorithms to drive simulators. Supra-threshold roll rates in the slalom task are also rated as more realistic. Overall, our findings suggest that higher tilt limits can be successfully implemented in motion cueing algorithms to better optimize simulator operational space.
@inproceedings{Nesti-2012-driving, author = {Nesti, A. and Masone, C. and Barnett-Cowan, M. and {Robuffo Giordano}, P. and Bülthoff, H. H. and Pretto, P.}, booktitle = {Driving Simulation Conference}, title = {Roll rate thresholds and perceived realism in driving simulation}, year = {2012}, volume = {}, number = {}, pages = {23-31}, doi = {}, keywords = {CyberMotion simulator}, }



2011
- Conference
 Bilateral teleoperation of multiple UAVs with decentralized bearing-only formation controlA. Franchi, C. Masone, H. H. Bülthoff, and P. Robuffo GiordanoIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2011
Bilateral teleoperation of multiple UAVs with decentralized bearing-only formation controlA. Franchi, C. Masone, H. H. Bülthoff, and P. Robuffo GiordanoIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2011We present a decentralized system for the bilateral teleoperation of groups of UAVs which only relies on relative bearing measurements, i.e., without the need of distance information or global localization. The properties of a 3D bearing-formation are analyzed, and a minimal set of bearings needed for its definition is provided. We also design a novel decentralized formation control almost globally convergent and able to maintain bounded and non-vanishing inter-distances among the agents despite the absence of direct distance measurements. Furthermore, we develop a multi-master/ multi-slave teleoperation setup in order to control the overall behavior of the group and to convey to the human operator suitable force cues, while ensuring stability in presence of delays and packet losses over the master-slave communication channel. The theoretical framework is validated by means of extensive human/hardware in-the-loop simulations using two force-feedback devices and a group of quadrotors.
@inproceedings{Franchi-2011-bearing, author = {Franchi, A. and Masone, C. and Bülthoff, H. H. and {Robuffo Giordano}, P.}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, title = {Bilateral teleoperation of multiple {UAVs} with decentralized bearing-only formation control}, year = {2011}, volume = {}, number = {}, pages = {2215-2222}, doi = {10.1109/IROS.2011.6094525}, keywords = {shared control, aerial robotics}, } - Conference
 Mechanical design and control of the new 7-DOF CyberMotion simulatorC. Masone, P. Robuffo Giordano, and H. H. BülthoffIn IEEE International Conference on Robotics and Automation (ICRA), Jun 2011
Mechanical design and control of the new 7-DOF CyberMotion simulatorC. Masone, P. Robuffo Giordano, and H. H. BülthoffIn IEEE International Conference on Robotics and Automation (ICRA), Jun 2011This paper describes the mechanical and control design of the new 7-DOF CyberMotion Simulator, a redundant industrial manipulator arm consisting of a standard 6-DOF anthropomorphic manipulator plus an actuated cabin attached to the end-effector. Contrarily to Stewart platforms, an industrial manipulator offers several advantages when used as motion simulator: larger motion envelope, higher dexterity, and possibility to realize any end-effector posture within the workspace. In addition to this, the new actuated cabin acts as an additional joint and provides the needed kinematic redundancy to cope with the robot actuator and joint range constraints, which in general can significantly deteriorate the desired motion cues the robot is reproducing. In particular, we will show that, by suitably exploiting the redundancy better results can be obtained in reproducing sustained acceleration cues, a relevant problem when implementing vehicle simulators.
@inproceedings{Masone-2011-mechanical, author = {Masone, C. and {Robuffo Giordano}, P. and Bülthoff, H. H.}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, title = {Mechanical design and control of the new {7-DOF} {CyberMotion} simulator}, year = {2011}, volume = {}, number = {}, pages = {4935-4942}, doi = {10.1109/ICRA.2011.5980436}, keywords = {CyberMotion simulator}, }


2010
- Conference
 A novel framework for closed-loop robotic motion simulation - part II: Motion cueing design and experimental validationP. Robuffo Giordano, C. Masone, J. Tesch, M. Breidt, L. Pollini, and H. H. BülthoffIn IEEE International Conference on Robotics and Automation (ICRA), Jun 2010
A novel framework for closed-loop robotic motion simulation - part II: Motion cueing design and experimental validationP. Robuffo Giordano, C. Masone, J. Tesch, M. Breidt, L. Pollini, and H. H. BülthoffIn IEEE International Conference on Robotics and Automation (ICRA), Jun 2010This paper, divided in two Parts, considers the problem of realizing a 6-DOF closed-loop motion simulator by exploiting an anthropomorphic serial manipulator as motion platform. After having proposed a suitable inverse kinematics scheme in Part I [1], we address here the other key issue, i.e., devising a motion cueing algorithm tailored to the specific robot motion envelope. An extension of the well-known classical washout filter designed in cylindrical coordinates will provide an effective solution to this problem. The paper will then present a thorough experimental evaluation of the overall architecture (inverse kinematics + motion cueing) on the chosen scenario: closed-loop simulation of a Formula 1 racing car. This will prove the feasibility of our approach in fully exploiting the robot motion capabilities as a motion simulator.
@inproceedings{Robuffo-2010b-cueing, author = {{Robuffo Giordano}, P. and Masone, C. and Tesch, J. and Breidt, M. and Pollini, L. and Bülthoff, H. H.}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, title = {A novel framework for closed-loop robotic motion simulation - part {II}: Motion cueing design and experimental validation}, year = {2010}, volume = {}, number = {}, pages = {3896-3903}, doi = {10.1109/ROBOT.2010.5509945}, keywords = {CyberMotion simulator}, } - Conference
 A novel framework for closed-loop robotic motion simulation - part I: Inverse kinematics designP. Robuffo Giordano, C. Masone, J. Tesch, M. Breidt, L. Pollini, and H. H. BülthoffIn IEEE International Conference on Robotics and Automation (ICRA), Jun 2010
A novel framework for closed-loop robotic motion simulation - part I: Inverse kinematics designP. Robuffo Giordano, C. Masone, J. Tesch, M. Breidt, L. Pollini, and H. H. BülthoffIn IEEE International Conference on Robotics and Automation (ICRA), Jun 2010This paper considers the problem of realizing a 6-DOF closed-loop motion simulator by exploiting an anthropomorphic serial manipulator as motion platform. Contrary to standard Stewart platforms, an industrial anthropomorphic manipulator offers a considerably larger motion envelope and higher dexterity that let envisage it as a viable and superior alternative. Our work is divided in two papers. In this Part I, we discuss the main challenges in adopting a serial manipulator as motion platform, and thoroughly analyze one key issue: the design of a suitable inverse kinematics scheme for online motion reproduction. Experimental results are proposed to analyze the effectiveness of our approach. Part II [1] will address the design of a motion cueing algorithm tailored to the robot kinematics, and will provide an experimental evaluation on the chosen scenario: closed-loop simulation of a Formula 1 racing car.
@inproceedings{Robuffo-2010-inverse, author = {Robuffo Giordano, P. and Masone, C. and Tesch, J. and Breidt, M. and Pollini, L. and Bülthoff, H. H.}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, title = {A novel framework for closed-loop robotic motion simulation - part {I}: Inverse kinematics design}, year = {2010}, volume = {}, number = {}, pages = {3876-3883}, doi = {10.1109/ROBOT.2010.5509647}, keywords = {CyberMotion simulator}, }

